
インデックスルールを使って完全一致を抽出する
このシナリオは、Talend Data Management Platform、Talend Big Data Platform、Talend Real Time Big Data Platform、Talend Data Services Platform、Talend MDM PlatformおよびTalend Data Fabricにのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
このシナリオでは、入力フローをインデックスに含まれるデータと照合することにより、顧客製品の一部の長い説明を標準化します。このシナリオでは、[Index] (インデックス)ルールを使って製品データをトークン化し、各トークンをインデックスと照合して完全一致を抽出する方法について説明します。
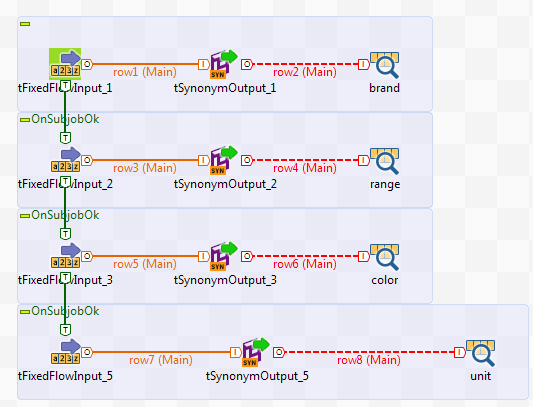
このシナリオでは、tSynonymOutputコンポーネントでジョブを使ってインデックスを最初に作成する必要があります。顧客製品のブランド、範囲、色、および単位のインデックスを作成する必要があります。tSynonymOutputコンポーネントを使ってインデックスを生成し、それらにエントリーとシノニムをフィードします。以下のキャプチャーは、ジョブの例を示しています。
以下は、このシナリオ用に生成されたインデックスのサンプルです。
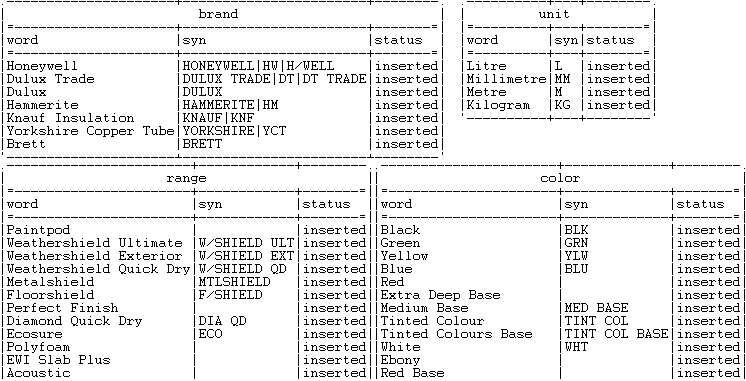
生成された各インデックスには、1つのカラムに文字列(単語のシーケンス)があり、2番目のカラムに対応するシノニムがあります。これらの文字列は、 tFixedFlowInputによって生成された製品データが照合される参照データとして使用されます。インデックス作成の詳細は、tSynonymOutputをご覧ください。
このシナリオでは、生成されたインデックスはコンテキスト変数として定義されます。コンテキスト変数の詳細は、 Studio Talendユーザーガイドをご覧ください。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。