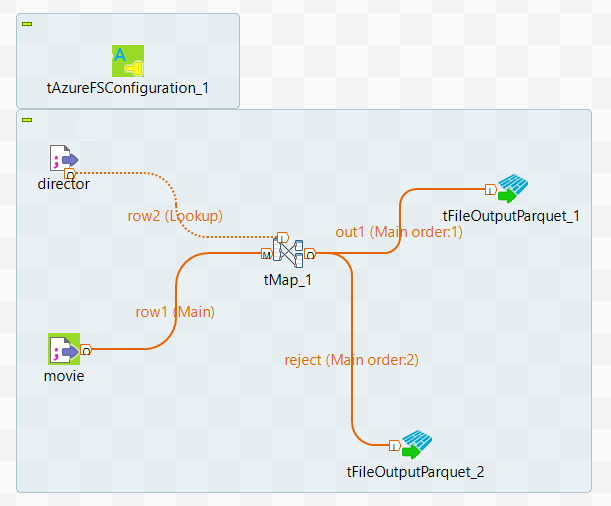
Apache Spark Batchフレームワーク内で実行されるデータ変換プロセスを設計するために、ジョブのワークスペース内でSpark Batchコンポーネントのオーケストレーションを行います。
手順
-
ジョブ内に使用するコンポーネントの名前を入力し、表示されるリストからこのコンポーネントを選択します。このシナリオでは、コンポーネントはtFileInputDelimitedコンポーネントが2つ、tMapコンポーネントが1つ、tFileOutputParquetコンポーネントが2つ、tAzureFSConfigurationコンポーネントが1つです。
-
tFileInputDelimitedコンポーネントは、映画データと監督データをDatabricksビッグデータプラットフォームのDBFSファイルシステムから現在のジョブのデータフローにロードするために使用されます。
-
tMapコンポーネントは入力データの変換に使用されます。
-
tFileOutputParquetコンポーネントは、Azure Data Lake Storageシステムのディレクトリーに結果を書き込みます。
- tAzureFSConfigurationコンポーネントは、Azure Data Lake Storageシステムへの接続に必要な情報を提供します。
-
2つのtFileInputDelimitedコンポーネントのうち1つをダブルクリックしてこのラベルを編集可能にし、movieと入力してこのコンポーネントのラベルを変更します。
-
directorのもう一方のラベルtFileInputDelimitedにも同じ手順を実行します。
-
movieのラベルが付いたtFileInputDelimitedコンポーネントを右クリックし、コンテキストメニューから[Row] (行) > [Main] (メイン)の順に選択し、tMapをクリックしてtMapに接続します。これは、映画データがtMapに送信される際のメインリンクです。
-
同様に、[Row] (行) > [Main] (メイン)リンクを使用し、director tFileInputDelimitedコンポーネントをtMapに接続します。これは、ディレクターデータがルックアップデータとしてtMapに送信される際の[Lookup] (ルックアップ)リンクです。
-
同様に、[Row] (行) > [Main] (メイン)リンクを使用してtMapコンポーネントをtFileOutputParquetコンポーネントに接続し、ポップアップウィザードで、このリンクにout1という名前を付け、[OK]をクリックしてこの変更を確定します。
-
これらのオペレーションを繰り返し、[Row] (行) > [Main] (メイン)リンクを使用してtMapコンポーネントをtFileOutputDelimitedコンポーネントに接続し、rejectという名前を付けます。
タスクの結果
ワークスペースではジョブ全体が以下のように表示されます。