
変換済みジョブを編集
コンポーネントを更新し、Spark Streamingフレームワーク内で実行されるデータ変換プロセスを確定します。
DBFSシステムの代わりにKafkaクラスターを使用して、ストリーミング映画データをジョブに提供します。ディレクターデータは、ルックアップフローでDBFSから引き続き取り込まれます。
始める前に
-
使用するDatabricksクラスターが正しく設定され、実行されています。
-
クラスターの管理者が、読み書き権限と、ユーザー名をDBFSおよびAzure ADLS Gen2ストレージシステム内の関連データとディレクトリーへのアクセスに使用する権限を付与していること。
手順
-
[Repository] (リポジトリー)でaggregate_movie_director_spark_streamingジョブをダブルクリックしてワークスペース内に開きます。
 アイコンは、元のジョブに使用されていたコンポーネントが現在のジョブフレームワーク(Spark Batch)内に存在しないことを示します。この例ではtHDFSInputとtHDFSOutputです。
アイコンは、元のジョブに使用されていたコンポーネントが現在のジョブフレームワーク(Spark Batch)内に存在しないことを示します。この例ではtHDFSInputとtHDFSOutputです。 -
tMapを右クリックし、コンテキストメニューから[Row] (行) > [out1]の順に選択し、新しいtFileOutputDelimitedをクリックして、tMapをこのコンポーネントに接続します。
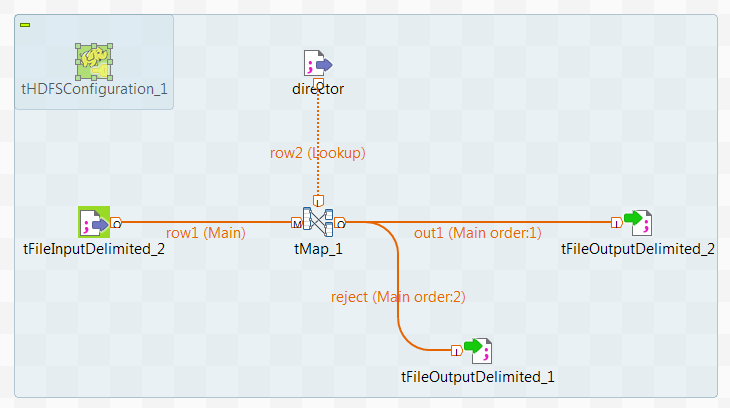
-
新しいtFileOutputDelimitedコンポーネントをダブルクリックし、その[Component] (コンポーネント)ビューを開きます。
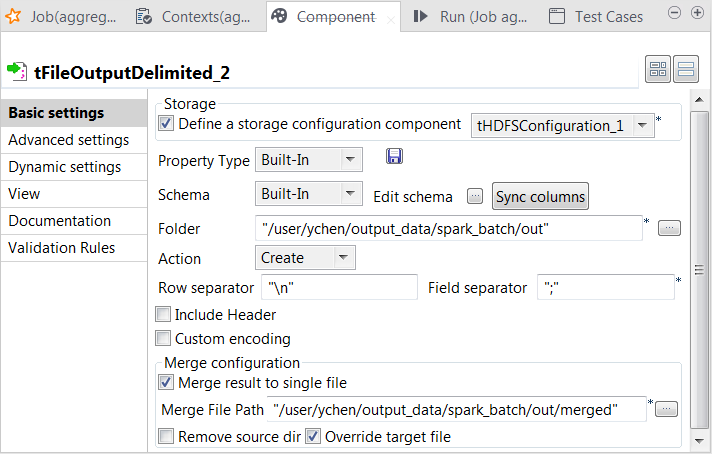
-
tMapから[reject] (リジェクト)リンクを受け取る別のtFileOutputDelimitedコンポーネントをダブルクリックし、その[Component] (コンポーネント)ビューを開きます。
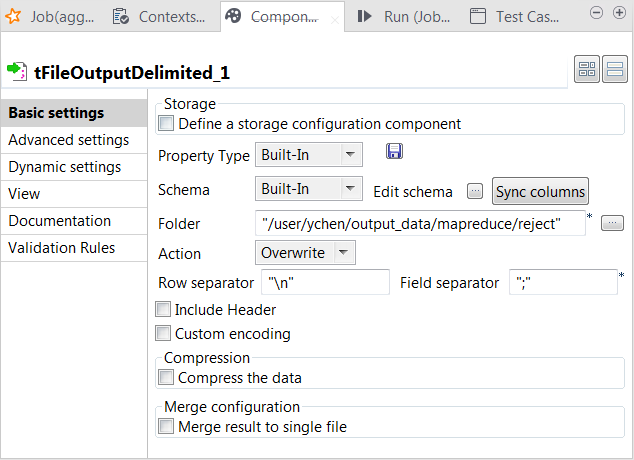
-
[Run] (実行)ビューで[Spark configuration] (Spark設定)タブをクリックし、Hadoop/Spark接続メタデータが元のジョブから適切に継承されていることを確認します。
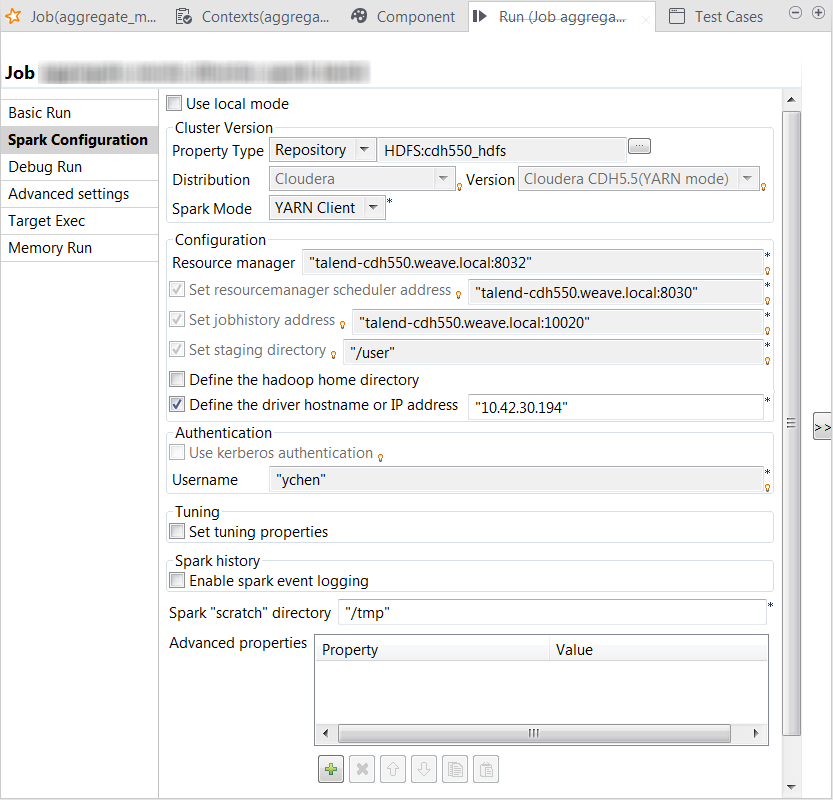
Spark Batchジョブに対する所定のHadoop/Sparkディストリビューションへの接続を定義するには、常にこの[Spark configuration] (Spark設定)タブを使用する必要があります。また、この接続はジョブごとに有効になります。
タスクの結果
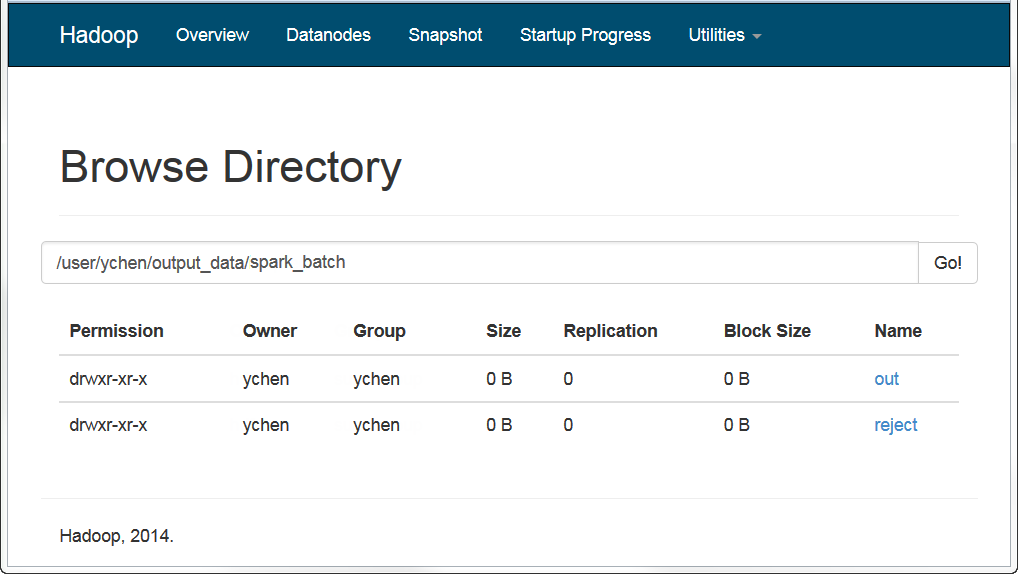
[Run] (実行)ビューがStudioの下側に自動的に開き、このジョブの実行の進行状況を示します。
ジョブが完了すると、たとえばHDFSシステムのWebコンソール内で、出力がHDFSに書き込まれていることを確認できます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。