
入力データを設定
DBFSからジョブにデータをロードするようにtFileInputDelimitedコンポーネントを設定します。
始める前に
-
ソースファイルmovies.csvとdirectors.txtがDBFS(Databricks File System)にファイルをアップロード (英語のみ)の説明に従ってHDFSにロードされていること。
-
[Repository] (リポジトリー)の[ delimited] (ファイル区切り)ノードの下で、movie.csvファイルのメタデータが設定されていること。
設定していない場合は、映画メタデータを準備 (英語のみ)を参照してメタデータを作成します。
手順
-
このスキーマメタデータノードをダブルクリックして、ウィザードを開きます。
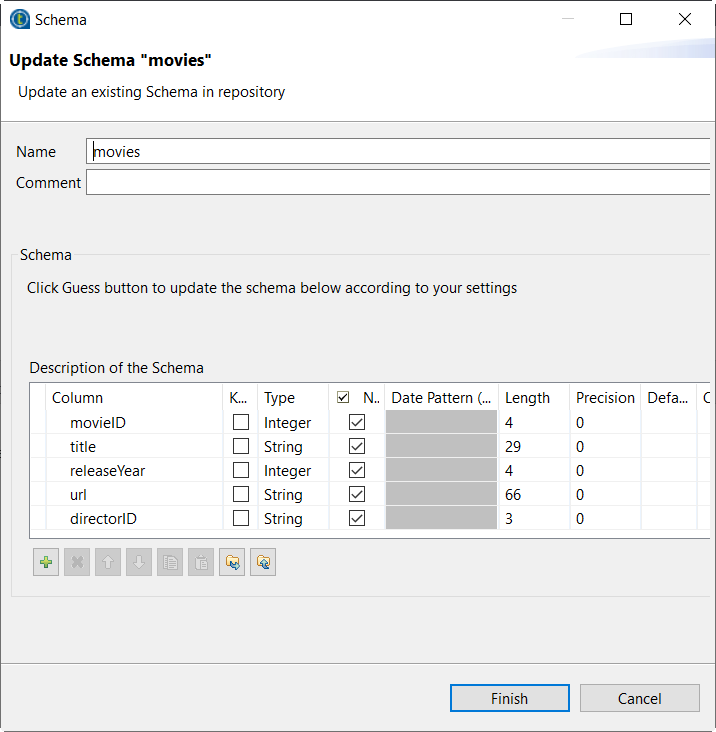
-
 ボタンをクリックして、スキーマをローカルディレクトリーにエクスポートします。
ボタンをクリックして、スキーマをローカルディレクトリーにエクスポートします。
-
movie tFileInputDelimitedコンポーネントをダブルクリックして[Component] (コンポーネント)ビューを開きます。
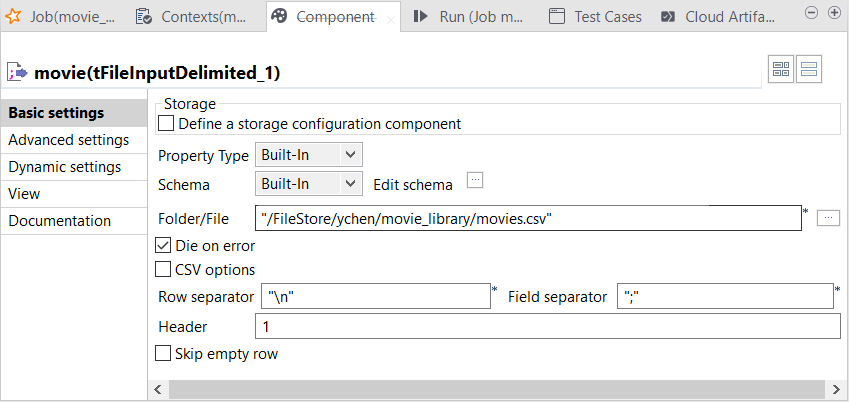
-
[Edit schema] (スキーマを編集)をクリックしてスキーマのエディターを開き、
 ボタンをクリックして、以前に[Repository] (リポジトリー)の[File delimited] (ファイル区切り)メタデータからエクスポートした映画データのスキーマをインポートします。
ボタンをクリックして、以前に[Repository] (リポジトリー)の[File delimited] (ファイル区切り)メタデータからエクスポートした映画データのスキーマをインポートします。
-
director tFileInputDelimitedコンポーネントをダブルクリックし、その[Component] (コンポーネント)ビューを開きます。
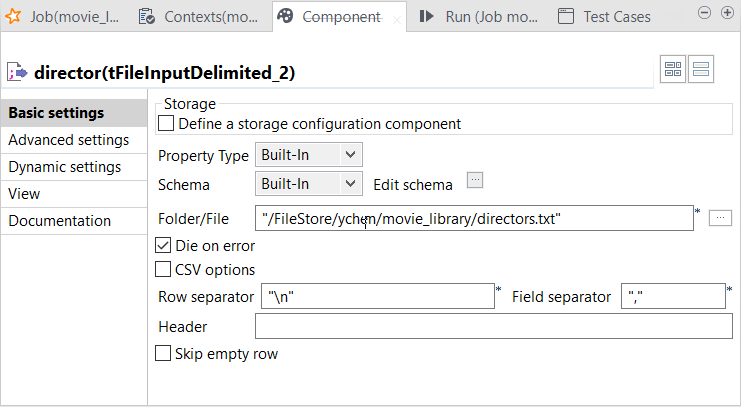
-
[+]ボタンを2回クリックして2つの行を追加し、[Column] (カラム)カラムで名前をそれぞれIDとNameに変更します。
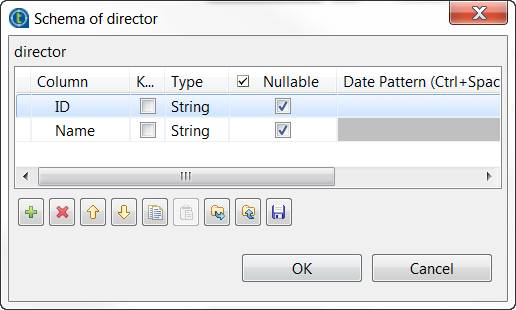
タスクの結果
これで、映画データとディレクターデータをジョブにロードするように入力コンポーネントが設定されました。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。