
分割ステップの設定
手順
-
分割ステップを表すリンクをクリックして、[Component] (コンポーネント)ビューを開き、[Parallelization] (並列化)タブをクリックします。
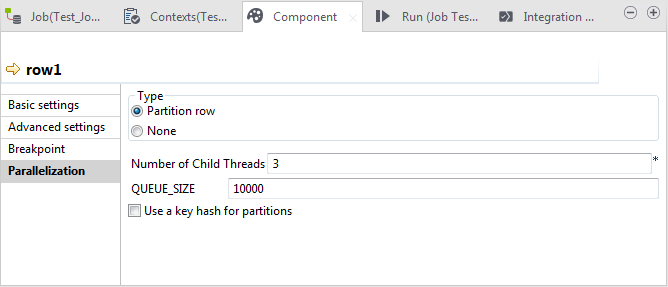 [Partition row]オプションは、[Type] (タイプ)エリアで自動的に選択されています。[None] (なし)オプションを選択すると、このリンクで処理するデータフローの並列化が無効になります。設定するリンクによっては、[Repartition row] (パーテーション行)オプションが[Type] (タイプ)エリアで利用可能となり、既に分割解除されているデータフローを再パーティショニングできます。この[Parallelization] (並列化)ビューでは、次のプロパティを定義する必要があります。
[Partition row]オプションは、[Type] (タイプ)エリアで自動的に選択されています。[None] (なし)オプションを選択すると、このリンクで処理するデータフローの並列化が無効になります。設定するリンクによっては、[Repartition row] (パーテーション行)オプションが[Type] (タイプ)エリアで利用可能となり、既に分割解除されているデータフローを再パーティショニングできます。この[Parallelization] (並列化)ビューでは、次のプロパティを定義する必要があります。-
[Number of Child Threads] (子スレッドの数): 入力レコードを複数スレッドに分割する場合のスレッド数。この数字はN-1にすることを推奨します。ここで、Nはデータを処理するマシンのCPU数またはコア数を表します。
-
[Buffer Size] (バッファーサイズ): 生成された各スレッドでキャッシュする行数。
-
[Use a key hash for partitions] (分割用にキーハッシュを使用): これによりハッシュモードを使って入力レコードをスレッドに転送できます。
これを選択すると、[Key Columns] (キーカラム)テーブルが表示されるため、ハッシュモードを適用するカラムをこのテーブルに設定します。ハッシュモードでは、同じ条件を満たすレコードが同じスレッドに転送されます。
このチェックボックスをオフにすると、転送モードは総当たり方式となり、レコードはローテーションで1件ずつ処理されて各スレッドに転送され、最後のレコードが転送されるまで続きます。このモードでは、同じ条件を満たすレコードが必ずしも同じスレッドに入らないことにご注意ください。
-
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。