
tSortRowの設定
手順
-
tSortRowをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
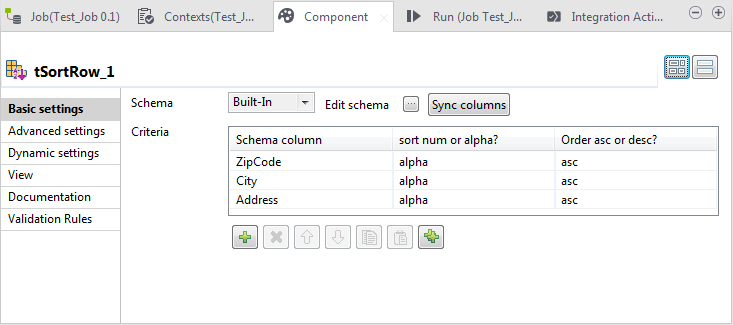
-
[Criteria] (条件)テーブルの下にある
 ボタンを3回クリックして、テーブルに3行を追加します。
ボタンを3回クリックして、テーブルに3行を追加します。
-
[Advanced settings] (詳細設定)をクリックして、ビューを開きます。
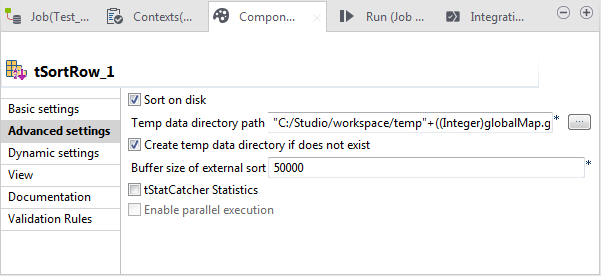
-
[Temp data directory path] (一時データディレクトリーパス)に、tSortRowで処理された一時データを格納するために使用するフォルダーのパスを入力するか、フォルダーを参照します。このアプローチを使うと、tSortRowが有効になり、より大量のデータをソートできます。
これらのスレッドを同じディレクトリーに書き出すと、互いに上書きしてしまうため、スレッドごとにフォルダーを作成してから、スレッドIDを使って処理する必要があります。スレッドIDを表す変数を使用するには、[Code] (コード)をクリックしてそのビューを開き、ビューの中でthread_idの変数を探す必要があります。この例では、この変数はtCollector_1_THREAD_IDとなります。
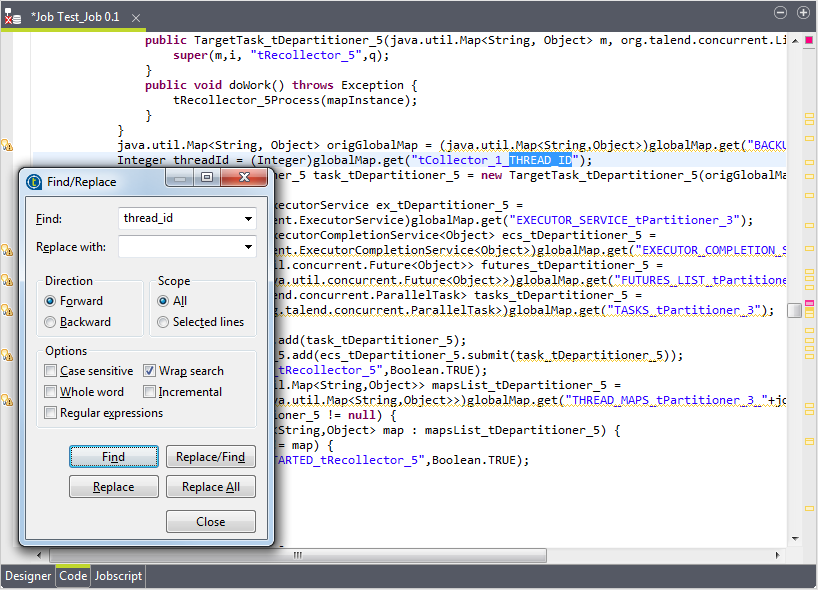 次にこの変数を使ってパスを入力する必要があります。次のようになります。"E:/Studio/workspace/temp"+((Integer)globalMap.get("tCollector_1_THREAD_ID"))。
次にこの変数を使ってパスを入力する必要があります。次のようになります。"E:/Studio/workspace/temp"+((Integer)globalMap.get("tCollector_1_THREAD_ID"))。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。