
データを重複除去するジョブの作成
Talend Studioメタデータの特定のファイルにあるデータを重複除去する既製ジョブを生成できます。この自動生成ジョブのコンポーネント設定を使用して、2つの個別のファイルまたはデータベースに重複値およびユニークな値を出力するように選択できます。
- 重複除去するファイルを選択します。
- 重複除去ジョブを実行するカラムを選択します。
- 必要に応じて、ブロックキーを定義して処理対象のデータを分割します。ブロックキーは、通常、ファイルに大量のデータが存在する場合に必要になります。
- ユニークなレコードおよび重複レコードを書き込む場所を選択します。
- 生成されたジョブを実行します。
手順
-
OKをクリックしてダイアログボックスを閉じます。
Talend Studioに[Cheat Sheet] (参照シート)パネルが表示されます。
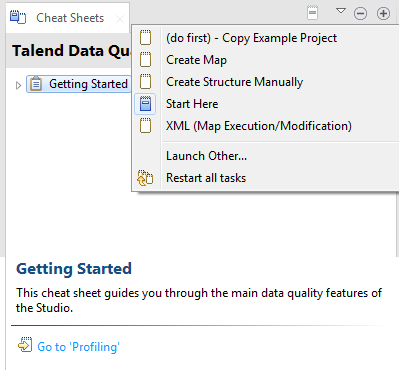
-
参照シートアイコンバーでドロップダウン矢印をクリックし、メニューから[Launch Other...] (その他を起動)を選択します。
[Cheat Sheet Selection] (参照シートの選択)ダイアログボックスが表示されます。
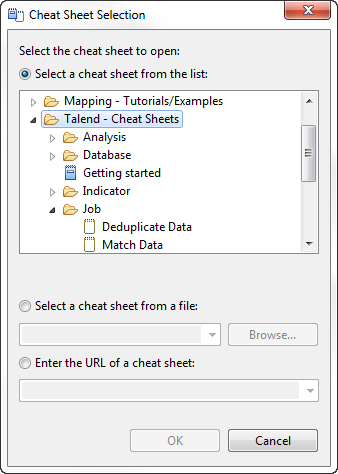
-
を展開して[Deduplicate Data] (データの重複除去)を選択し、OKをクリックしてダイアログボックスを閉じます。
対応するページが[Cheat Sheet] (参照シート)パネルに表示されます。このページでは、特定のファイルの特定のカラムに対して既製ジョブを作成する方法を段階的に説明します。
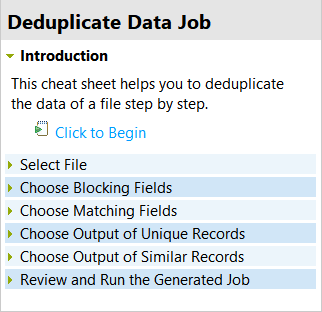
-
紹介文を読んで、[Click to Begin] (クリックして開始)をクリックします。
処理の最初の手順[Select File] (入力ファイルの選択)が展開されます。
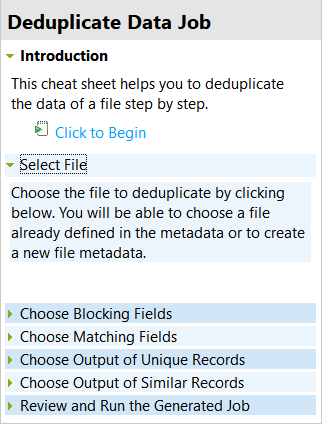
-
メタデータ接続からクレンジングを行うファイルを選択し、OKをクリックします。
参照シートの次のステップが展開します。
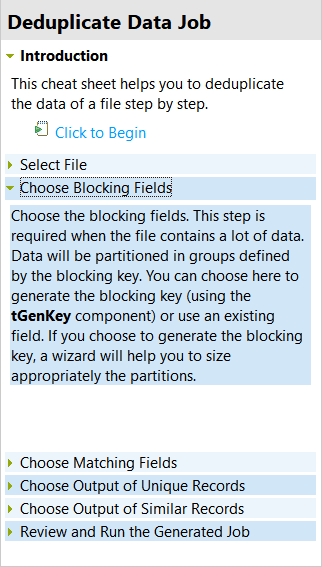
-
指示に従い、最後のステップである[Review and Run the Generated Job] (生成されたジョブを確認して実行)になるまでウィザードと参照シートページのステップを切り替えます。
このウィザードでは、さまざまなビューで定義された設定に応じて、リポジトリーのすべてのコンポーネントおよびメタデータを設定し、ジョブを生成します。Talend StudioはIntegrationパースペクティブに切り替わり、次のように生成されたジョブが表示されます。
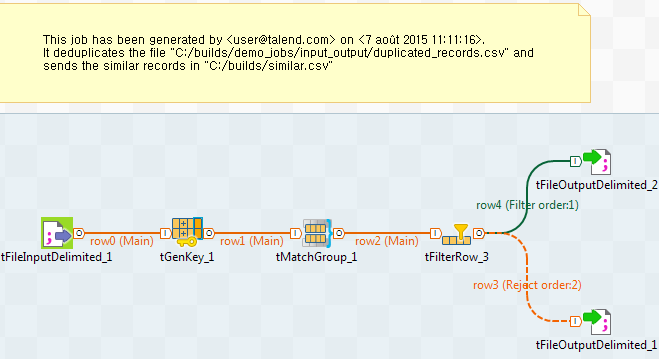
タスクの結果
ファイルの一意値および重複値が特定され、指定された出力ファイルまたはデータベースに保存されます。生成されたジョブは、[Repository] (リポジトリー)ツリービューの[Job Designs] (ジョブデザイン)ノードの下に保存されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。