
Cloudera Navigatorを使ってデータ来歴を設定
Cloudera Navigatorに対するサポートがTalend Sparkジョブに追加されました。
ジョブの実行にCloudera V5.5+を使用している場合は、Cloudera Navigatorを利用して特定のデータフローの来歴をトレースし、このジョブに使用されているコンポーネントおよびコンポーネント間のスキーマの変更を含め、このデータがSparkジョブによってどう生成されたかを確認できます。
たとえば、以下のジョブをデザインし、それに関する来歴情報を生成するとします。
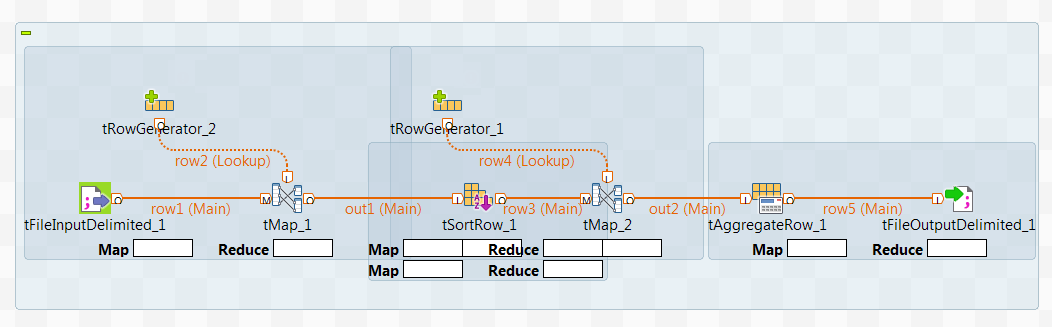
手順
タスクの結果
この時点までに、Cloudera Navigatorへの接続がセットアップ済みとなっています。このジョブを実行する時は、Cloudera Navigator内に来歴が自動的に生成されています。
ジョブを正しく実行するには、[Spark configuration] (Spark設定)タブでさらにその他のパラメーターを設定する必要があります。
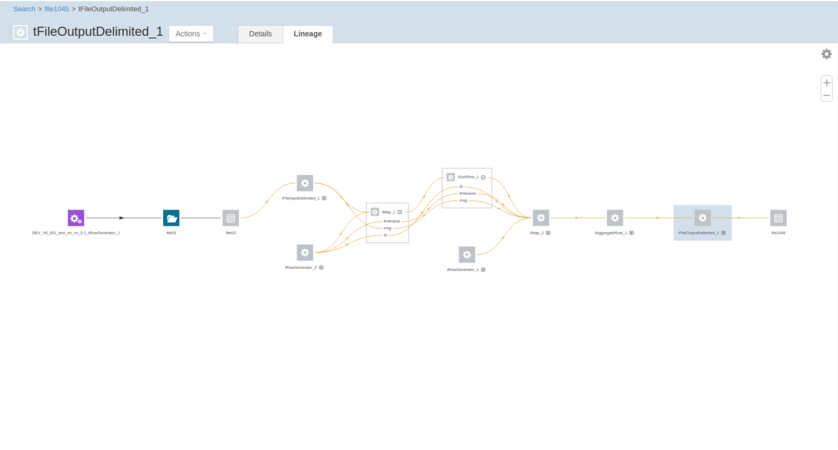
ジョブの実行が完了したら、このジョブによって書かれたデータをCloudera Navigatorで検索し、Cloudera Navigatorでこのデータの来歴を確認します。
この来歴グラフをStudio内のジョブと比較すると、すべてのコンポーネントがこのグラフに表示されていることが確認できます。また、各コンポーネントのアイコンを展開し、使用されているスキーマを読むことができます。
Cloudera NavigatorではClouderaSDKライブラリー (英語のみ)を使用して機能が提供されるため、このSDKライブラリーのバージョンと互換性があるはずです。Cloudera Navigatorのバージョンは、ClouderaディストリビューションによってインストールされたCloudera Managerによって決まります。また、Navigatorのバージョンに基づいて、対応しているSDKが自動的に使用されます。
ただし、Cloudera Navigatorのバージョンによっては、対応しているSDKのバージョンがない場合があります。Cloudera SDKのバージョンと互換性があるNavigatorのバージョンの詳細は、Cloudera NavigatorとSDKバージョンの互換性 (英語のみ)に関するClouderaのドキュメンテーションをご覧ください。
StudioでサポートされているCloudera Navigatorバージョンの詳細は、サポートされているCloudera Navigatorのバージョンをご覧ください。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。