
Sparkで使うS3サービスに接続を設定
手順
-
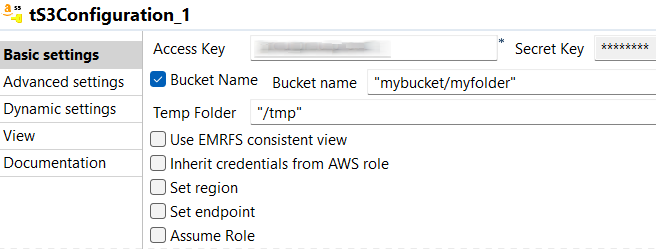
tS3Configurationをダブルクリックして[Component] (コンポーネント)ビューを開きます。
Sparkはこのコンポーネントを使って、ジョブが実際のビジネスデータを書き込むS3システムに接続します。Databricks on AWSをサポートするtS3Configurationもその他の設定コンポーネントも配置していない場合、このビジネスデータはDatabricksファイルシステム(DBFS)で書かれます。
例
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。