
tJavaFlexを使ってW3C拡張ログ形式にあるダイナミックヘッダーを処理する方法
| Version (バージョン) | 現在サポートされているすべてのエンタープライズおよびプラットフォームバージョン(データ統合バッチジョブ) |
環境
- この記事は、Studio Talend for Data Integration 6.3.1 (Enterprise)を使って作成されました。したがって、添付されたジョブは、Talendバージョン6.3.1以降でのみインポートされます。
- tJavaFlexコンポーネントは、Studio Talendの現在サポートされているすべてのバージョンで使えます。
W3C拡張ログ形式
W3Cによると、拡張ログ形式には、ディレクティブ(ヘッダー)とエントリー(データ)の2種類の行が含まれています。各エントリー行にはフィールドのリストが含まれ、ディレクティブにはログ自体に関するメタデータが含まれています。Fieldsディレクティブは、行エントリーのログデータを読み取るために解析する必要があるフィールドのリストを具体的に保持します。
以下はログの例です。Fields ディレクティブの3行目に注目してください。W3Cログのフィールドはスペースで区切られています。
#Version: 1.0
#Date: 2001-05-02 17:42:15
#Fields: time cs-method cs-uri-stem sc-status cs-version
17:42:15 GET /default.htm 200 HTTP/1.0
17:42:15 GET /default.htm 200 HTTP/1.0
ソリューション
フィールドと値はスペースで区切られているため、tFileInputDelimitedコンポーネントを使って上記のファイルを読み取ることができます。最初の3行をスキップするようにコンポーネントを設定し、フィールド区切りとしてスペース文字を含む行エントリーを読み取ります。ただし、このソリューションの課題は、管理者がログに出力されるフィールドの順序または名前を変更した場合、正しいカラムが正しいフィールドにマップされるように動的に適応しないことです。目的は、IT管理者がログによって出力されているフィールドの順序や名前をどのように変更したかに関係なく、常に正しいフィールドをマップすることです。既知のフィールドを読み取ってマッピングし、新しいフィールドや未知のフィールドを無視するソリューションを設計する理由がここにあります。定義から削除された既存のフィールドは、ジョブでnull値を送信します。
ソリューションは、tJavaFlexを使ってフィールドを正しくマッピングすることです。以下のことを行います。
- フィールドディレクティブを見つけてフィールドリストを読み取る
- 行ごとにログエントリーを読み取る
- ログエントリーを解析する
- ログエントリーのフィールドを、スキーマで定義されているフィールドにマッピングする。新規、不明、および欠落しているフィールドは無視します。ソリューションは、必要なデータ型解析も実行します
tJavaFlexのしくみ
tJavaFlexでは、パーソナライズされたコードを入力して、これをTalend Data Integrationジョブに統合できます。tJavaFlexを使うと、目的の処理を実行するコンポーネントを構成する3つのJavaコード部分(start、main、end)を入力できます。3つの部分(開始、メイン、終了)を正しくコーディングすることで、Talendはロジックがサブジョブのデータフロー内で予想通りに動作するようにします。tJavaFlexの詳細は、コンポーネントのドキュメントをご覧ください。
ジョブを作成
以下に示すように、tJavaFlexコンポーネントおよびtLogRowコンポーネントを使ってジョブを作成します。

入力ファイルのパスを参照する新しいコンテキスト変数inputFileを作成します。tJavaFlexコンポーネントコードでコンテキスト変数を使います。
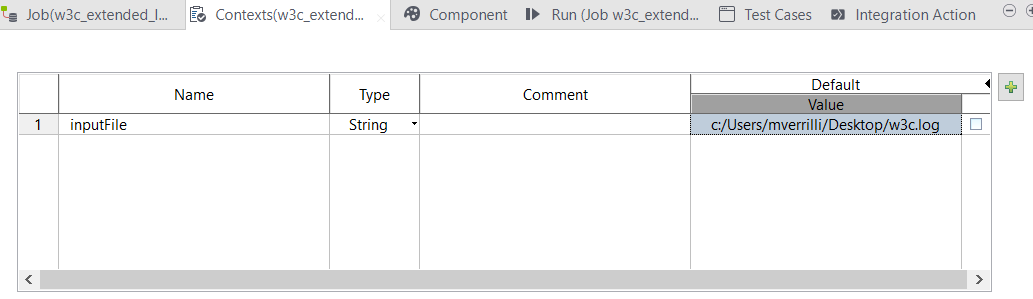
スキーマを定義する
この例では、次のフィールドに注目します: time cs-method cs-uri-stem sc-status cs-version 。スキーマフィールド名はTalend標準に準拠しており、Talendのスキーマエディターでダッシュを含めることはできないため、ダッシュの代わりにアンダースコアを使います。マッピングはtJavaFlexコンポーネントのMainセクションで行われるため、名前は一致する必要がありません。ロジックを最適化しておくために、ログエントリーから抽出するフィールドのみをマッピングしています。これは、データ統合ジョブを設計する時のベストプラクティスです。必要なデータを操作してメモリにロードするだけです。
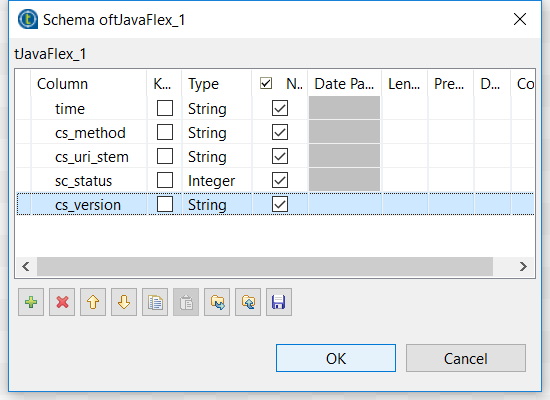
tJavaFlexコンポーネントを設定する
最初にStart Codeを定義します。インラインコメントは手順をより詳細に説明しますが、ファイルパスのコンテキスト変数 inputFileの使用に注目してください。
概要:
- 変数を宣言する
- BufferedReaderを使ってファイルを開く
- フィールドのディレクティブをスキャンし、リストを解析して配列にする
- ループを開始してデータ行を処理する
Start Code
// In order to add new fields not currently supported,
// simply add the field to this component's schema,
// then at the switch statement in the main code,
// add the relevant mapping and data type conversion
// if required.
// input file is set via context variable
String file = context.inputFile;
// Raw line from file before being parsed
String line = "";
// Split line variable for parsed data
String[] parts;
// List of fields
String[] fieldList = {};
// lineCount to assist in case a specific line causea an exception
Long lineCount = new Long(0);
// errorLineCount to report a summary of the number of rows rejected due to errors
Long errorLineCount = new Long(0);
// Read the file and fill out the field list.
try (BufferedReader br = new BufferedReader(new FileReader(file)))
{
while ((line = br.readLine()) != null) {
lineCount++; // process the line.
if ( line.startsWith("#") ) {
System.out.println(line);
// If the fields directive is found, parse fields to an array
if ( line.startsWith("#Fields: ") ) {
fieldList = line.substring(9).split(" ");
break;
}
}
else {
// throw error to abort
throw new Exception("Field list not detected.");
}
}
// Process remaining file as data lines
while ((line = br.readLine()) != null) {
次に、Main Codeの各行を処理します。必須フィールドごとにswitchステートメントがサポートされていることに注目してください: time cs-method cs-uri-stem sc-status cs-version。Main Code
lineCount++;
// Skip directives
if ( line.startsWith("#") ) {
continue;
}
try {
// parse the line
parts = line.split(" ");
// initialize new row
row1 = new row1Struct();
// Populate each field by position
for( int ii = 0; ii < fieldList.length; ii++) {
switch ( fieldList[ii] ) {
case "time" :
row1.time = parts[ii];
break;
case "sc-status" :
row1.sc_status = Integer.parseInt(parts[ii]);
break;
case "cs-method" :
row1.cs_method = parts[ii];
break;
case "cs-uri-stem" :
row1.cs_uri_stem = parts[ii];
break;
case "cs-version" :
row1.cs_version = parts[ii];
break;
default:
log.warn("Unhandled field encountered [" + fieldList[ii] + "].");
System.out.println("Unhandled field encountered [" + fieldList[ii] + "].");
}
}
} catch (java.lang.Exception e) {
//output exception for each log entry that causes an issue and continue to read next line
log.warn("tJavaFlex_1 [Line " + lineCount + "] " + e.getMessage());
System.err.println(e.getMessage());
errorLineCount++;
continue;
}
次に、End Codeセクションのデータ処理ループを閉じます。ここでは、いくつかの有用な統計をログに出力したり、リジェクトされた行について警告したりする機会もあります。
End Code
}
}
log.info("tJavaFlex_1 - " + lineCount + " rows processed.");
if (errorLineCount > 0) {
log.warn("tJavaFlex_1 - " + errorLineCount + " rows rejected.");
}
最後に、必要なインポートを、使用するライブラリーの詳細設定のImportセクションに追加する必要があります。
Imports
import java.io.BufferedReader; import java.io.FileReader;
ジョブを実行する
ジョブを実行すると、各行のtLogRow出力と共にヘッダーがログに(printlnステートメントにより)出力されます。追加のログデータを表示するには、[Run] (実行)タブで[Advanced Settings] (詳細設定)を定義します: log4jLevel => Info.
Starting Job w3c_extended_log_test at 17:45 10/02/2017.
[INFO ]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - TalendJob:
'w3c_extended_log_test' - Start.
[statistics] connecting to socket on port 3935
[statistics] connected
#Version: 1.0
#Date: 2001-05-02 17:42:15
#Fields: time cs-method cs-uri-stem sc-status cs-version
[INFO ]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Content of row 1:
17:42:15|GET|/default.htm|200|HTTP/1.0
17:42:15|GET|/default.htm|200|HTTP/1.0
[INFO
]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Content of row 2:
17:42:15|GET|/default.htm|200|HTTP/1.0
17:42:15|GET|/default.htm|200|HTTP/1.0
[INFO
]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tJavaFlex_1 - 5 rows
processed.
[INFO ]:
sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Printed row count:
2.
[statistics]
disconnected
[INFO ]:
sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - TalendJob: 'w3c_extended_log_test'
- Done.
Job w3c_extended_log_test ended at 17:45
10/02/2017. [exit code=0]結論
tJavaFlexコンポーネントはTalendのパワフルな機能であり、幅広い拡張性を実現します。この例は、入力ファイル形式にある程度の柔軟性を与える方法を示しています。この単一のtJavaFlex実装は、新しいフィールドの追加、フィールドの転置、予測可能な結果を伴うフィールドの欠落など、さまざまな形式で受信データを処理できます。
詳細は、tJavaFlexおよびExtended Log File Formatをご覧ください。このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。