
メタデータを使ってHDFSからデータを読み取り
tHDFSInputコンポーネントを使えば、HDFSからデータを読み取れます。
始める前に
- このチュートリアルではHadoopクラスターを活用します。Hadoopクラスターが利用可能であることが必要です。
- HDFSメタデータも設定済みであること(Hadoopクラスターのメタデータ定義を作成とHadoopクラスターのメタデータ定義をインポートをご覧ください)。
- HDFSにデータが書き込まれていること(メタデータを使ってHDFSにデータを書き込みをご覧ください)。
手順
-
[Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックします。
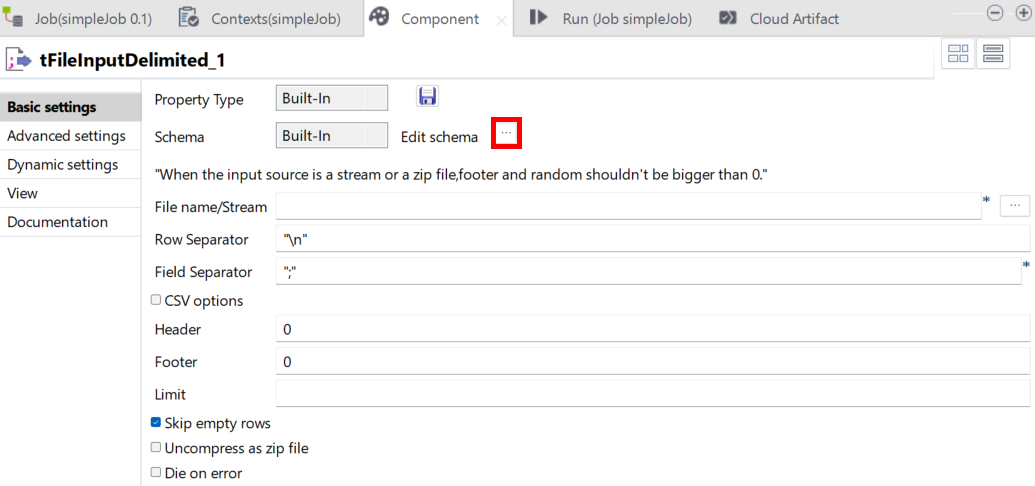
-
tSortRowコンポーネントを右クリックします。
-
tLogRowコンポーネントをクリックし、2つのコンポーネントをリンクします。
[Designer] (デザイナー)は次のようになります。
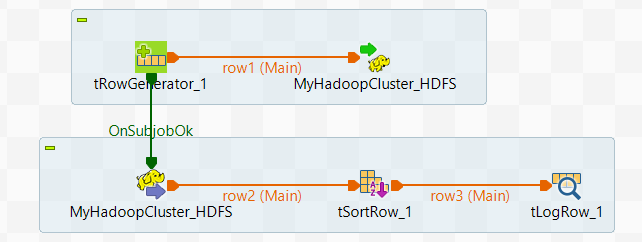
-
tLogRowコンポーネントをクリックし、2つのコンポーネントをリンクします。
タスクの結果
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。