
都市内の事故が発生しやすい地域をモデリングする
このシナリオは、サブスクリプションベースのビッグデータ対応のTalend製品にのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
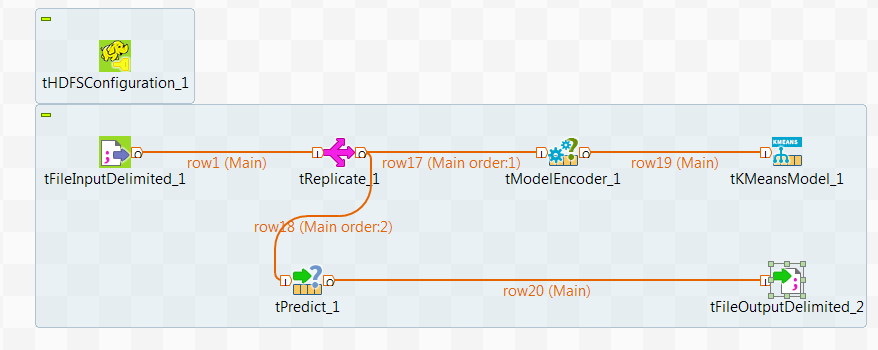
このシナリオでは、tKMeansModelコンポーネントを使って、事故が発生しやすい地域をモデリングするために、都市内の救急車の目的地に関するサンプル地理データセットを分析します。
このようなモデルは、病院の建設に最適な場所を判断するのに役立ちます。
このサンプルデータはここからダウンロードできます。緯度と経度のペアで構成されます。
サンプルデータは、デモンストレーションのみを目的としてランダムに自動生成されたものであり、いかなる場合も、現実の世界におけるこれらの領域の状況を反映するものではありません。
-
使うSparkのバージョンは1.4以降です。
-
サンプルデータがHadoopファイルシステムに保管されており、少なくともそれを読み取るための適切な権限とアクセス権があること。
-
Hadoopクラスターが正しくインストールされ、実行中であること。
-
tFileInputDelimited: サンプルデータをジョブのデータフローに読み取ります。
-
tReplicate: サンプルデータを複製し、複製をキャッシュします。
-
tKMeansModel: データを分析してモデルをトレーニングし、モデルをHDFSに書き込みます。
-
tModelEncoder: データを前処理して、tKMeansModelで使う適切な特徴ベクトルを準備します。
-
tPredict: サンプルデータの複製にK-meansモデルを適用します。現実の世界では、このデータは、モデルの精度をテストするための参照データセットである必要があります。
-
tFileOutputDelimited: 予測の結果をHDFSに書き込みます。
-
tHDFSConfiguration: このコンポーネントは、ジョブに依存するjarファイルの転送先となるHDFSシステムに接続するために、Sparkによって使用されます。
[Run] (実行)ビューの[Spark configuration] (Spark設定)タブで、ジョブ全体でのSparkクラスターへの接続を定義します。また、ジョブでは、依存jarファイルを実行することを想定しているため、Sparkがこれらのjarファイルにアクセスできるように、これらのファイルの転送先にするファイルシステム内のディレクトリーを指定する必要があります。-
Yarnモード(YarnクライアントまたはYarnクラスター):
-
Google Dataprocを使用している場合、[Spark configuration] (Spark設定)タブの[Google Storage staging bucket] (Google Storageステージングバケット)フィールドにバケットを指定します。
-
HDInsightを使用している場合、[Spark configuration] (Spark設定)タブの[Windows Azure Storage configuration] (Windows Azure Storage設定)エリアでジョブのデプロイメントに使用するブロブを指定します。
- Altusを使用する場合は、[Spark configuration] (Spark設定)タブでジョブのデプロイにS3バケットまたはAzure Data Lake Storageを指定します。
-
オンプレミスのディストリビューションを使用する場合は、クラスターで使われているファイルシステムに対応する設定コンポーネントを使用します。一般的に、このシステムはHDFSになるため、tHDFSConfigurationを使用します。
-
-
[Standalone mode] (スタンドアロンモード): クラスターで使われているファイルシステム(tHDFSConfiguration Apache Spark BatchやtS3Configuration Apache Spark Batchなど)に対応する設定コンポーネントを使用します。
ジョブ内に設定コンポーネントがない状態でDatabricksを使用している場合、ビジネスデータはDBFS (Databricks Filesystem)に直接書き込まれます。
-
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。