
分類モデルを適用する
手順
-
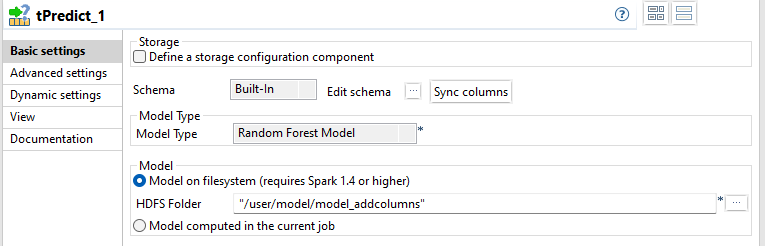
tPredictをダブルクリックして[Basic settings] (基本設定)を開きます。
-
[Model on filesystem] (ファイルシステムのモデル)ラジオボタンを選択し、使う分類モデルが保管されているディレクトリーを入力します。
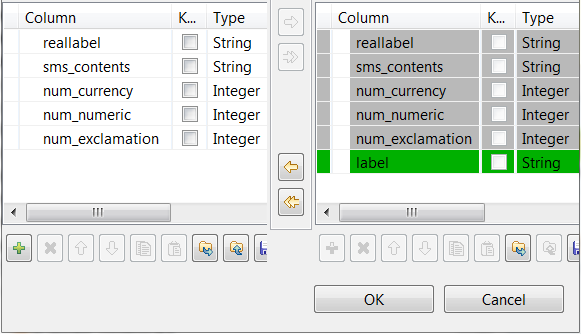
tPredictコンポーネントには、labelと呼ばれる読み取り専用のカラムが含まれています。このモデルでは分類プロセスで使われるクラスが提供されますが、入力スキーマから取得されたreallabelカラムには、各メッセージが実際に属するクラスが含まれています。各メッセージの実際のラベルをモデルが決定するラベルと比較することにより、モデルが評価されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。