
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| 標準ジョブでIcebergテーブル形式をサポートする新しいコンポーネント | Talend Studioの標準ジョブでIcebergコンポーネントが利用できるようになりました。次のコンポーネントによって、JDBCを介し、Icebergと互換性があるデータベースで作業できるようになります:
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.4.xでスタンドアロンモードをサポート | [Standalone] (スタンドアロン)モードのSpark 3.4.xで、Spark Universalを使ってSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはSpark対応のカスタマイズ済みクラスターに接続してそのクラスターからジョブを実行します。 この機能のベータ版では、HiveとHBaseはサポートされていません。現在のところ、Avroコンポーネントが含まれるSparkジョブはサポートされていません。 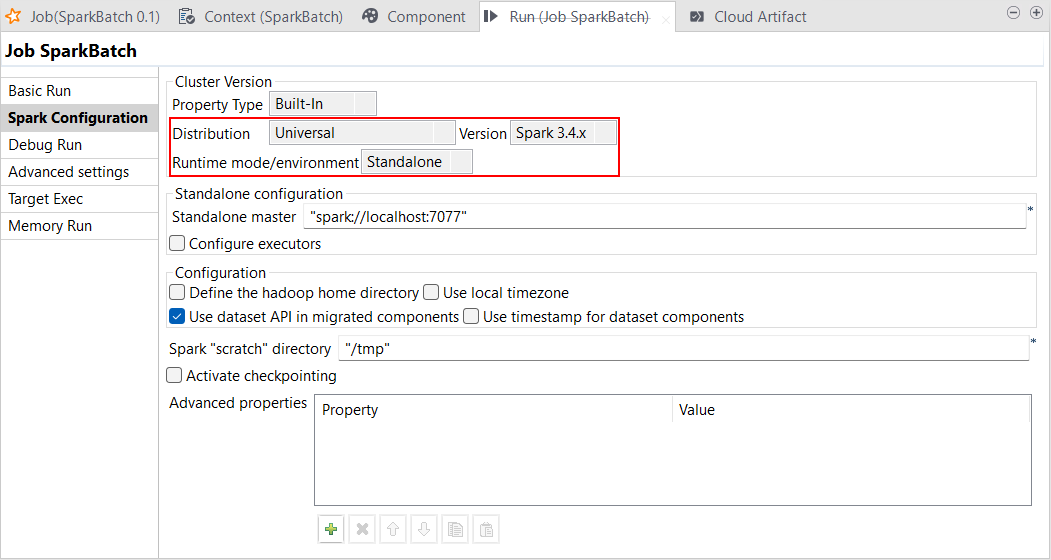
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark 3.3.xでCDP Private Cloud Base 7.1.8をサポート | Spark 3.3.xでCDP Private Cloud Base 7.1.8がサポートされるようになりました。CDP Private Cloud Base 7.1.8では、Spark UniversalでYarnクラスターモードを使ってSparkジョブを実行できます。 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。