
S3システムにDatabricksからアクセスするためにS3固有のプロパティを追加する
S3固有のプロパティをAWS上のDatabricksクラスターのSpark設定に追加します。
始める前に
- DatabricksのSparkクラスターが正しく作成され、実行されていることと、バージョンが3.5 LTSであることを確認します。詳細は、DatabricksドキュメンテーションでCreate Databricks workspaceをご覧ください。
- AWSアカウントを持っていること。
- 使用するS3バケットが適切に作成されており、それにアクセスするための適切な権限があること。
- Machine Learning コンポーネントかtMatchPredictを使用している場合は、Databricks Runtime Versionの設定がX.X LTS MLになっていること。
手順
-
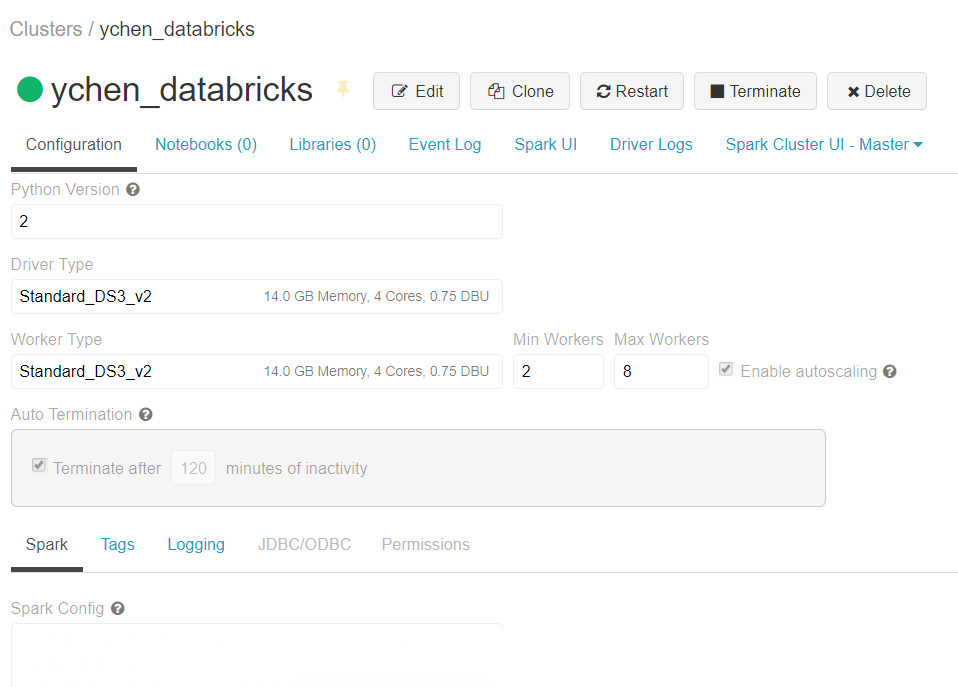
Databricksクラスター ページの[Configuration] (設定)タブで、ページ下部の[Spark] (スパーク) タブまでスクロールします。
例
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。