
ジョブを変換
既存のSpark BatchジョブからSpark Streamingジョブへの変換
始める前に
-
Studio Talendを起動し、Integrationパースペクティブを開いていること。
-
Apache Spark Batchジョブを使って映画とディレクターの情報を結合で説明されているSpark Batchジョブaggregate_movie_director_sparkが作成済みで、正しく実行されていること。
手順
-
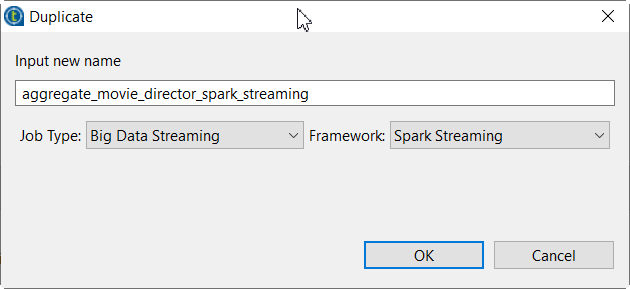
aggregate_movie_director_sparkジョブを右クリックし、コンテキストメニューから[Duplicate] (複製)を選択します。
[Duplicate] (複製)ウィンドウが開きます。
タスクの結果
この新しいSpark Streamingジョブは、さらに編集できる状態になっています。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。