
Big Dataプラットフォームに接続を設定
ビッグデータプラットフォームへの接続を[Repository] (リポジトリー)に設定すると、同じプラットフォームを使用するたびに接続を設定する必要がなくなります。
この例で使用するビッグデータプラットフォームは、Azure Data Lake Storage Gen2と共にDatabricks V5.4クラスターです。
始める前に
-
データブリックのSparkクラスターが正しく作成されていること。
詳細は、AzureドキュメンテーションでCreate Databricks workspaceを参照してください。
- Azureアカウントを持っています。
- Azure Data Lake Storage Gen2のストレージアカウントが適切に作成されており、適切な読み取りおよび書き込み権限が与えられていること。この種類のストレージアカウントの作成方法の詳細は、AzureドキュメントからAzure Data Lake Storage Gen2を有効にしてストレージアカウントを作成するを参照してください。
-
Integrationパースペクティブがアクティブであること。
このタスクについて
手順
-
Databricksクラスター ページの[Configuration] (設定)タブで、ページ下部の[Spark] (スパーク) タブまでスクロールします。
例
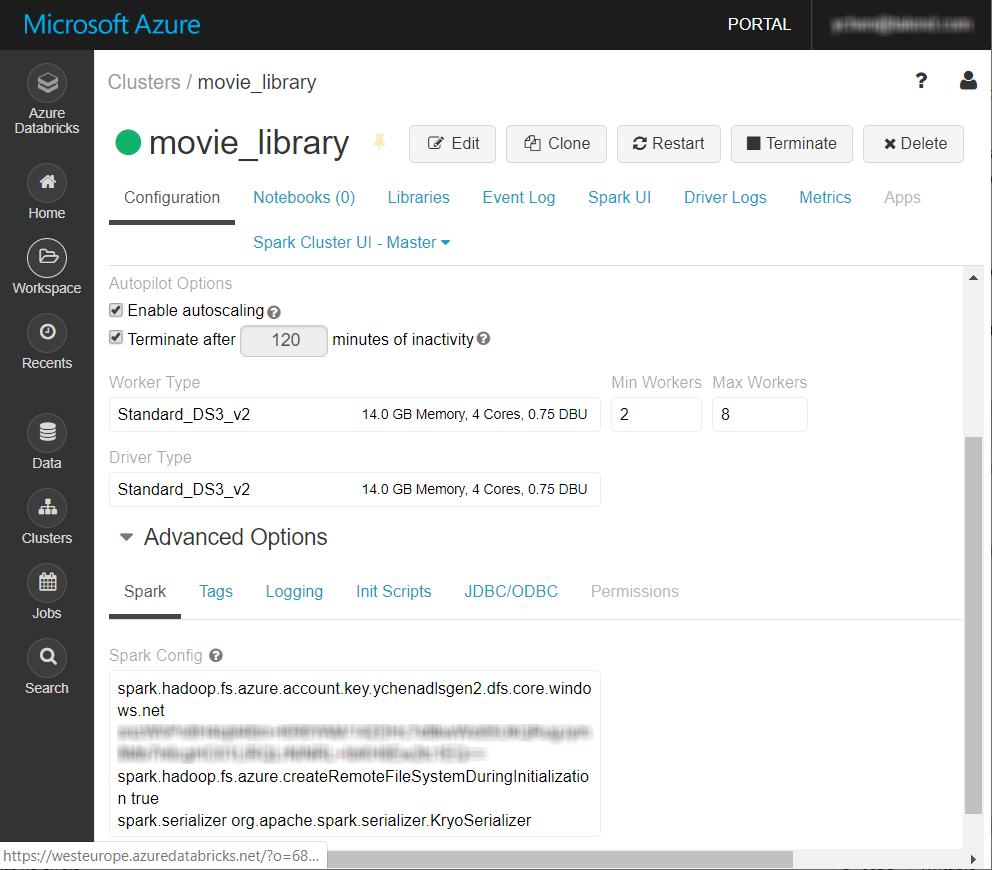
-
[Enter manually Hadoop services] (Hadoopサービスを手動で入力)チェックボックスをオンにして、作成するDatabricks接続の設定情報を手動で入力します。
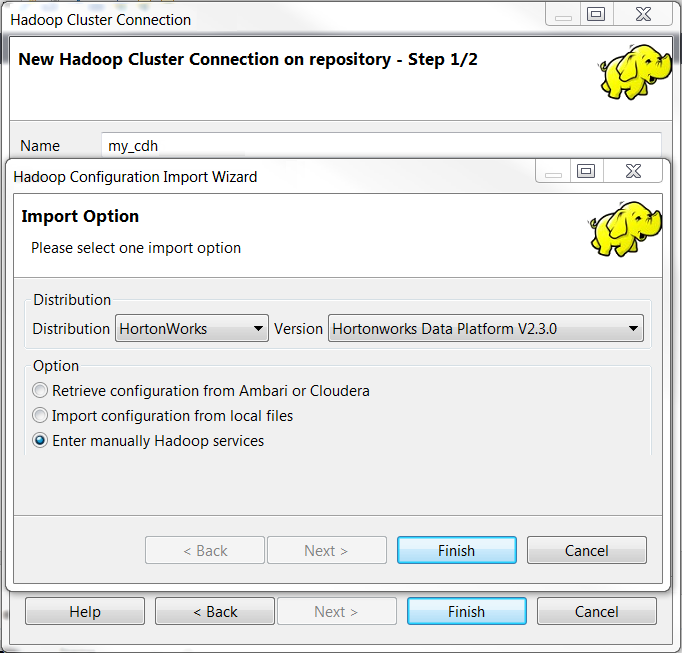
タスクの結果
新しい接続この例ではmovie_library という名前が、[Repository] (リポジトリー)ツリービューの[Hadoop cluster] (Hadoopクラスター)フォルダーの下に表示されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。