
HCatalogへの接続の作成
手順
-
接続ウィザードが表示されます。ここで、[Name] (名前)、[Purpose] (目的)、[Description] (説明)など、ジェネリックプロパティを入力します。[Status] (ステータス)フィールドは、[File] (ファイル) > [Edit project properties] (プロジェクトプロパティを編集)で定義できます。
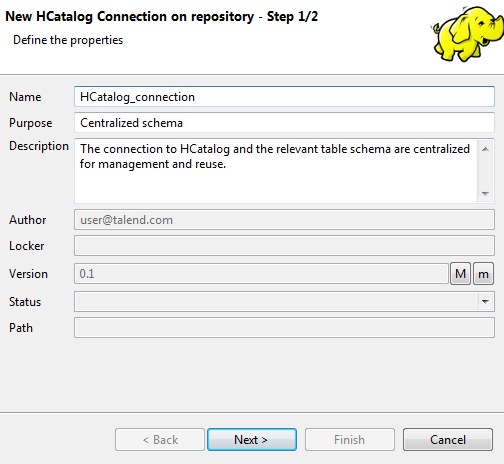
-
完了したら、[Next] (次へ)をクリックします。次の手順では、HCatalogの接続データを入力します。このうち、[Host name] (ホスト名)には、前の手順で選択したHadoop接続から継承された値が自動的に入力されます。Templetonの[Port] (ポート)と[Database] (データベース)は、デフォルトの値を使用します。
このデータベースはHiveデータベースで、Templeton (WebHcat)はHCatalogでコマンドを発行するために、RESTに類似したWeb APIとして使用します。Templeton (WebHCat)の詳細は、Apacheのドキュメンテーションをご覧ください。
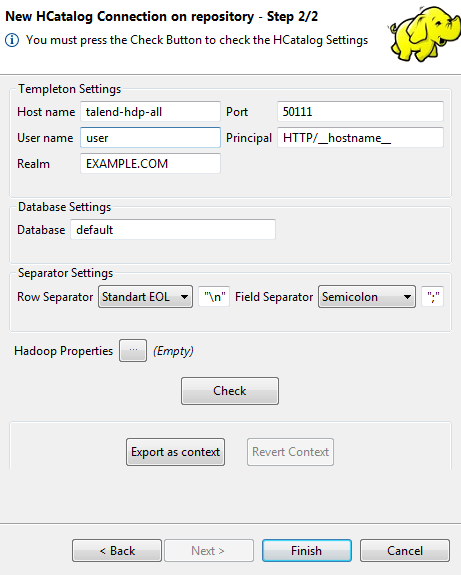 [ Principal] (プリンシパル)フィールドと[Realm] (領域)フィールドは、使用しているHadoop接続でKerberosセキュリティが有効な場合にのみ表示されます。これらのフィールドは、KerberosでHCatalogクライアントとHCatalogサーバーを相互に認証するために必要なプロパティです。情報メモ注:
[ Principal] (プリンシパル)フィールドと[Realm] (領域)フィールドは、使用しているHadoop接続でKerberosセキュリティが有効な場合にのみ表示されます。これらのフィールドは、KerberosでHCatalogクライアントとHCatalogサーバーを相互に認証するために必要なプロパティです。情報メモ注:Hadoopサーバーのホスト名をクライアントやホストのコンピューターで識別可能にするには、クライアントとホストのコンピューターの関連するhostsファイルにそのホスト名でIPアドレスとホスト名のマッピングエントリーを追加する必要があります。たとえば、Hadoopサーバーのホスト名がtalend-all-hdpで、IPアドレスが192.168.x.xの場合、マッピングエントリーは192.168.x.x talend-all-hdpとなります。Windowsシステムでは、このエントリーをC:\WINDOWS\system32\drivers\etc\hostsに追加します(WindowsがCドライブにインストールされている場合)。Linuxシステムでは、このエントリーを/etc/hostsのファイルに追加します。
-
[Finish] (終了)をクリックして変更を確定します。
作成したHCatalogの接続は、[Repository] (リポジトリー)ツリービューの[Hadoop cluster] (Hadoopクラスター)ノードの下に表示されます。
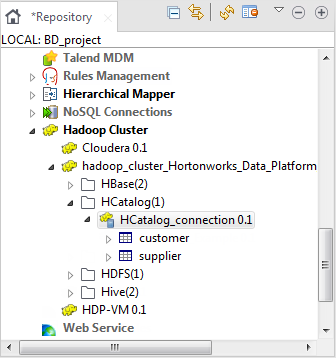 情報メモ注: この[Repository] (リポジトリー)ビューは、使用しているTalend Studioのエディションによって異なる場合があります。環境コンテキストを使用してこの接続のパラメーターを定義する必要がある場合は、[Export as context] (コンテキストとしてエクスポート)ボタンをクリックして対応するウィザードを開き、以下のオプションから選択します。
情報メモ注: この[Repository] (リポジトリー)ビューは、使用しているTalend Studioのエディションによって異なる場合があります。環境コンテキストを使用してこの接続のパラメーターを定義する必要がある場合は、[Export as context] (コンテキストとしてエクスポート)ボタンをクリックして対応するウィザードを開き、以下のオプションから選択します。-
[Create a new repository context] (新しいリポジトリーコンテキストを作成): 現在のHadoop接続からこの環境コンテキストを作成します。つまり、ウィザードで設定するパラメーターは、これらのパラメーターに設定した値と共にコンテキスト変数として取られます。
-
[Reuse an existing repository context] (既存のリポジトリーコンテキストを再利用): 特定の環境コンテキストの変数を使用して現在の接続を設定します。
この[Export as context] (コンテキストとしてエクスポート)機能の使い方に関するステップバイステップの説明は、メタデータのコンテキストとしてエクスポート、およびコンテキストパラメーターを再利用して接続を設定をご覧ください。
-
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。