
一致結果を表示
このタスクについて
定義する一致タイプ(この例では[Levenshtein]と[Jaro-Winkler])に基づいて入力フローから重複値を収集するには、次の手順に従います。
手順
-
一致分析エディターで設定を保存し、F6を押します。
分析が実行されます。データセット全体に対してマッチングルールとブロッキングキーが計算され、エディターで[Analysis Results] (分析結果)ビューが開きます。
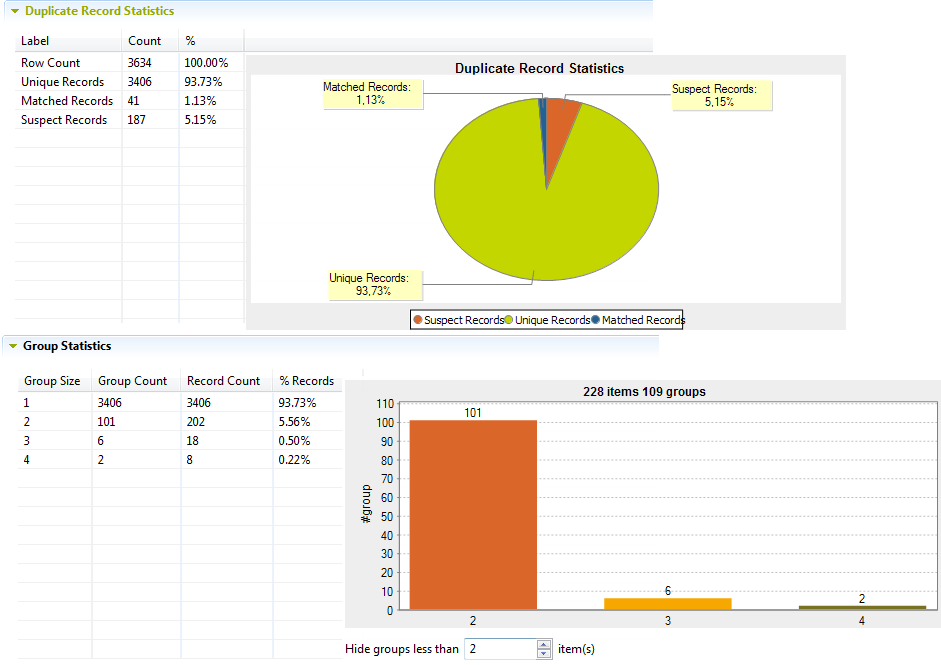 このビューのチャートから、分析されたデータの重複値の全体図がわかります。最初のテーブルには、処理されたレコード、重複を除いた一意レコード、重複レコード(一致したレコード)、ルールに一致しなかった疑わしいレコードに関する統計が表示されます。重複レコードは、良好なスコア(信頼しきい値を越えている)と一致したレコードを表します。一致したペアの1つのレコードが破棄すべき重複で、もう1つがサバイバーレコードです。2番目のテーブルには、グループ数と各グループ内のレコード数に関する統計が表示されます。テーブルのカラムヘッダーをクリックすると、クリックしたヘッダーに従って結果がソートされます。
このビューのチャートから、分析されたデータの重複値の全体図がわかります。最初のテーブルには、処理されたレコード、重複を除いた一意レコード、重複レコード(一致したレコード)、ルールに一致しなかった疑わしいレコードに関する統計が表示されます。重複レコードは、良好なスコア(信頼しきい値を越えている)と一致したレコードを表します。一致したペアの1つのレコードが破棄すべき重複で、もう1つがサバイバーレコードです。2番目のテーブルには、グループ数と各グループ内のレコード数に関する統計が表示されます。テーブルのカラムヘッダーをクリックすると、クリックしたヘッダーに従って結果がソートされます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。