
HTTPクライアントを使ったデータの抽出方法に関する追加情報
[
{
"name": "Peter",
"age": 40,
"male": true,
"addresses": {
"city": "Nantes",
"zip": "44000",
"street": "bd prairie au duc"
},
"cars": [
{"brand": "Ford", "model": "Transit", "km": 123456},
{"brand": "Renault", "model": "Clio", "km": 87234}
]
},
{
"name": "Emma",
"age": 34,
"male": true,
"addresses": {
"city": "Paris",
"zip": "75000",
"street": "bd Saint-Germain"
},
"cars": [
{"brand": "Tesla", "model": "Model 3", "km": 63456},
{"brand": "Ford", "model": "Mustang Mach-E", "km": 32543},
{"brand": "Volkswagen", "model": "Golf 8", "km": 43876},
]
}
][Extract a sub-part of the response] (レスポンスのサブ部分を抽出)
この設定はレスポンスのペイロード全体を処理し、 返したいサブエレメントを抽出します。セレクターが配列を指す場合、項目ごとに出力レコードを1つ生成します。
| [Extract a sub-part of the response] (レスポンスのサブ部分を抽出)の値 | 結果 |
|---|---|
|
<empty> または. または.root (この3つの値は同じ結果を返します) |
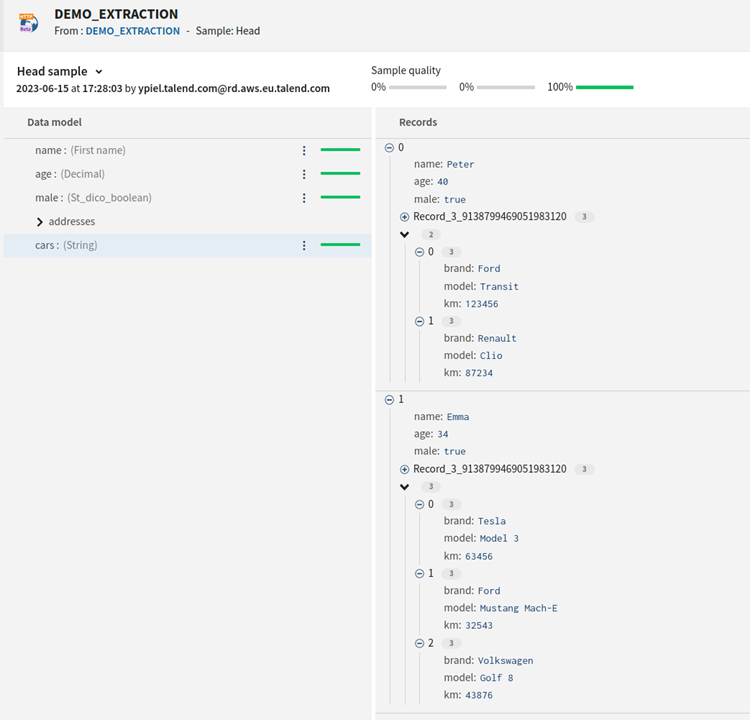
|
|
.root[1] ドキュメントが配列(で開始されで終了])で、そこから項目を1つだけを抽出したい場合は、.rootを使えばインデックスを定義できます。確かに.[1]と[1]は有効ではありませんが、.root[1]はドキュメントの2番目のエレメント(インデックスは0から開始)を抽出します。 |
|
|
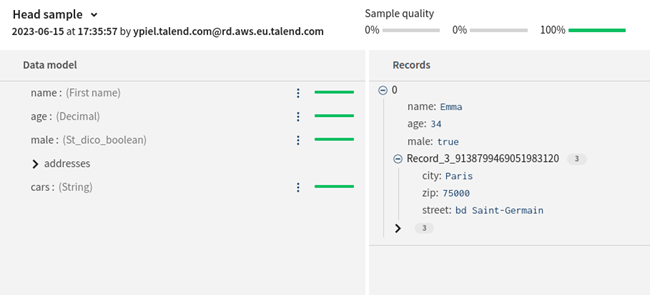
.root[1].cars 部分配列を選択してループさせることができます。ここでは、Emmaが所有する自動車のリストが選択されています。 |

|
|
.root[1].cars{.km > 40000} 返されたエレメントをフィルタリングできます。ここでは、Emmaが所有し、40000kmを超えている車のリストが返されます。 |
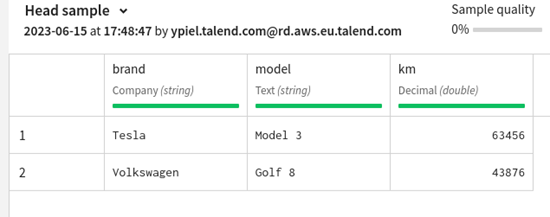
|
[Output key/value pair] (出力キー/値のペア)
[Extract a sub-part] (サブ部分を抽出)パラメーターを使ってメインデータが抽出されたら、値をいくつか抽出してフラットレコードを作成することもできます。
これを行うには、[Output key/value pairs] (出力キー/値のペア)を有効にし、[Name] (名前) / [Value] (値)エントリーを追加します。[Name] (名前)は出力レコードのフィールド名となり、[Value] (値)にはコネクターに設定されたHTTPクエリーのレスポンスから値を取得するためのDSSLセレクターが含まれます。
この例では、[Extract a sub-part of the response value] (レスポンスのサブ部分を抽出)値が . なので、PeterとEmmaという2つのレコードがループされます。
| 名前 / 値 | 結果 |
|---|---|
|
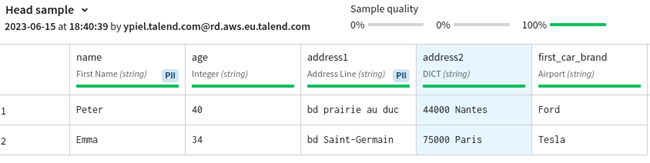
|
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。