
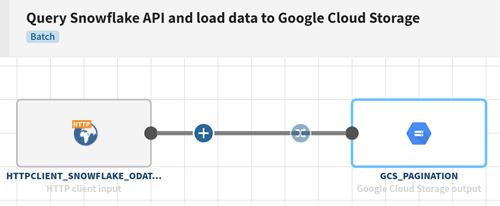
Snowflake APIをクエリーしてGoogle Cloud Storageにデータを送信
始める前に
手順
-
HTTPクライアントのプロパティの説明に従って、呼び出すAPIの接続プロパティとURLアドレスを入力します。
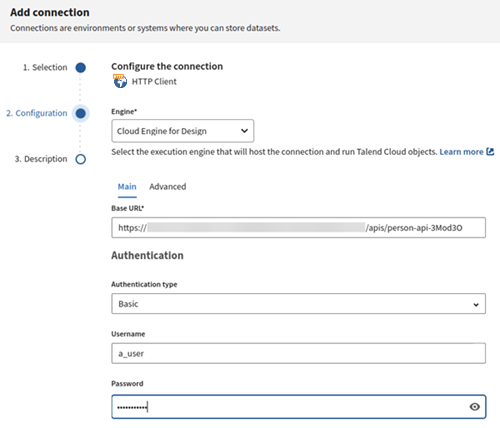
- [Base URL] (ベースURL): Snowflake APIのサマリーに記載されているベースURLをコピーして貼り付けます。
- [Authentication type] (認証タイプ): Basicを選択します。
- APIへの接続に必要な認証情報(ユーザー名とパスワード)を入力します。
- 接続をオンにして[Next] (次へ)をクリックします。
-
データセットに名前を付け、必須のプロパティを入力し、既存のバケットにGoogle Cloud Storage Blobを作成します。
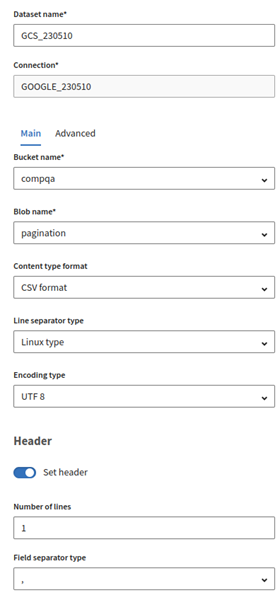
- [Bucket name] (バケット名): 既存のバケット名を選択します。
- [Blob name] (Blob名): まだ存在しない名前を入力します。
- [Content type format] (コンテンツタイプ形式): [CSV format] (CSV形式)を選択します。
- [Line separator type] (行区切りタイプ): [Linux type] (Linuxタイプ)を選択します。
- [Encoding type] (エンコーディングタイプ): UTF-8を選択します。
- [Set header] (ヘッダーを設定)オプションを有効にし、[Number of lines] (行数)に1を、[Field separator type] (フィールド区切りのタイプ)に , をそれぞれ入力します。
タスクの結果
パイプラインが実行中となります。Snowflakeテーブルの11行目からの行がすべてGoogle Cloud Storageのファイルにコピーされ、ODATA APIを経由して5行ずつ取得されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。