
ドライバーに関するデータセットから固定サイズのサンプルを抽出
始める前に
-
ソースデータを保管するシステムへの接続が作成済みであること。
ここでは、テスト接続を使用します。
-
ソースデータを保管するデータセットが追加済みであること。
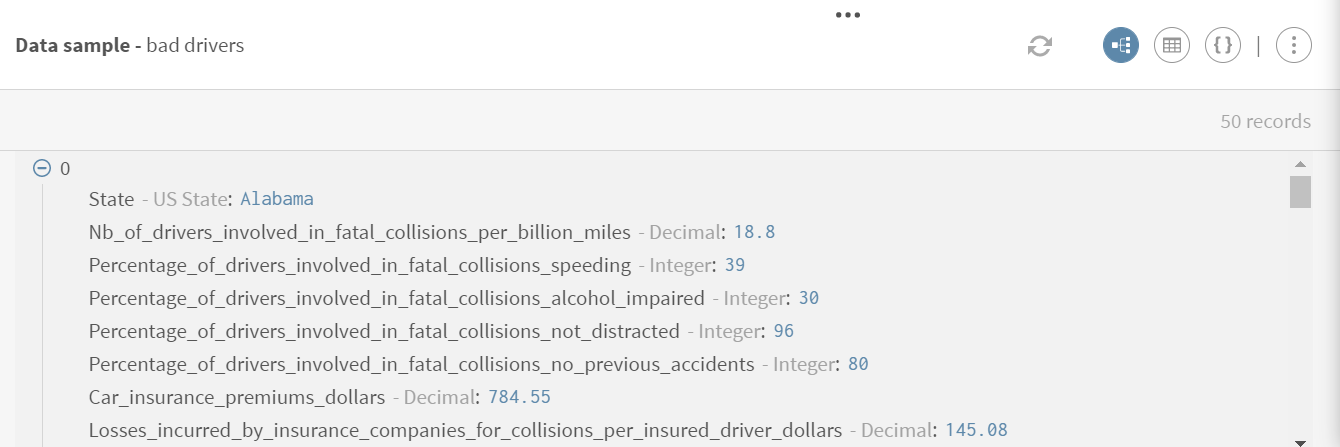
sampling-drivers.zipファイルをダウンロードして抽出します。問題ある運転者に関するデータ(速度、アルコール、注意散漫による死亡衝突事故に関わった運転者の割合や自動車保険の情報など)を持つデータセットが含まれています。
-
接続および処理済みデータを保管する関連データセットも作成済みであること。
また、出力フォルダーはFTPサーバーに保存されています。
手順
-
[ADD SOURCE] (ソースを追加)をクリックしてパネルを開きます。このパネルで、ソースデータ(この場合は死亡衝突事故に関わった運転者に関するデータと保険データ)を選択できます。
例
-
 をクリックし、パイプラインにData samplingプロセッサーを追加します。設定パネルが開きます。
をクリックし、パイプラインにData samplingプロセッサーを追加します。設定パネルが開きます。
-
[Save] (保存)をクリックして設定を保存します。
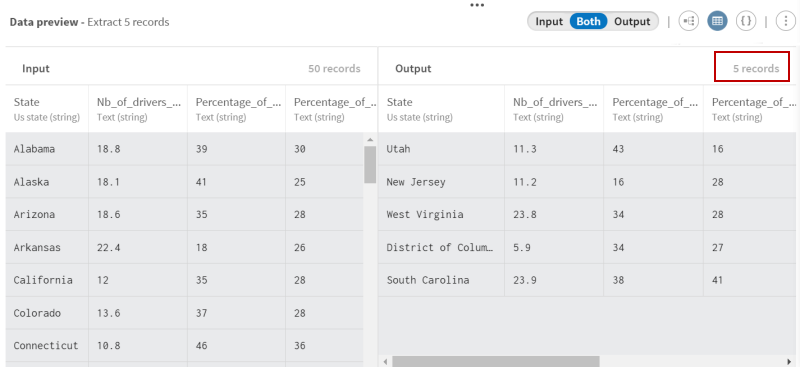
プロセッサーのプレビューに注目し、操作前のデータと結合後のデータを比較します。
ランダムに選択された5つのレコードだけが含まれるサブセットが出力に作成されていることがわかります。
タスクの結果
パイプラインは実行中となり、指定したレコード数に基づいてデータのサブセットが作成され、指定したFTPフォルダーに出力が送られます。これらのデータのサブセットはデータサイエンティストが予測分析に使用します。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。