
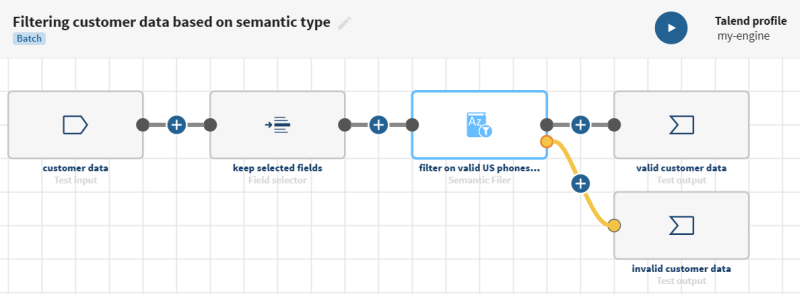
有効なセマンティックタイプと無効なセマンティックタイプに基づいて顧客データをフィルタリング
始める前に
-
ソースデータを保管するシステムへの接続が作成済みであること。
ここでは、テスト接続を使用します。
-
ソースデータを保管するデータセットが追加済みであること。
semantic_filter-customers.zipファイルをダウンロードして抽出します。このドキュメントに添付されるローデータを持つ顧客リストが含まれています。
-
接続および処理済みデータを保管する関連データセットも作成済みであること。
ここでは、ファイルは2つのテストデータセットにも保管されます。
手順
-
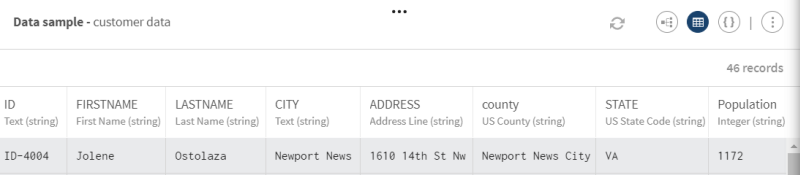
[ADD SOURCE] (ソースを追加)をクリックしてパネルを開きます。このパネルで、ソースデータ(この場合は生データ(整合性のないフィールドの小文字と大文字、空のフィールドなど)を含む顧客のリストと事前発見済みのセマンティックタイプ)を選択できます。
例
-
 をクリックし、パイプラインにField selectorプロセッサーを追加します。設定パネルが開きます。
をクリックし、パイプラインにField selectorプロセッサーを追加します。設定パネルが開きます。
-
[Configuration] (運用設定)タブから:
-
[Simple] (シンプル)選択モードで
![[Edit] (編集)](/ja-JP/pipeline-designer-processors-guide/Cloud/Content/Resources/images/icon-open-dialog.png) アイコンをクリックし、ツリービューを開きます。ここで、保持したいフィールドを選択して名前を変更できます。
アイコンをクリックし、ツリービューを開きます。ここで、保持したいフィールドを選択して名前を変更できます。
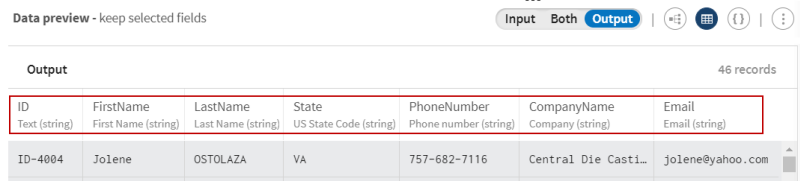
- ツリービューで[ID]、[FIRSTNAME]、[LASTNAME]、[STATE]、[company_name]、[EMAIL]というフィールドを選択します。
-
そのフィールドの横にある
![[Rename] (名前を変更)](/ja-JP/pipeline-designer-processors-guide/Cloud/Content/Resources/images/icon-blue_pencil.png) アイコンをクリックし、それぞれID、Firstname、Lastname、State、CompanyName、Emailと名前を変更します。
アイコンをクリックし、それぞれID、Firstname、Lastname、State、CompanyName、Emailと名前を変更します。
-
[Simple] (シンプル)選択モードで
-
[Save] (保存)をクリックして設定を保存します。
プロセッサーのプレビューに注目し、選択操作と名前変更操作の前後のデータを比較します。
-
をクリックし、パイプラインにSemantic filterプロセッサーを追加します。[Configuration] (設定)パネルが開きます。
-
[Save] (保存)をクリックして設定を保存します。
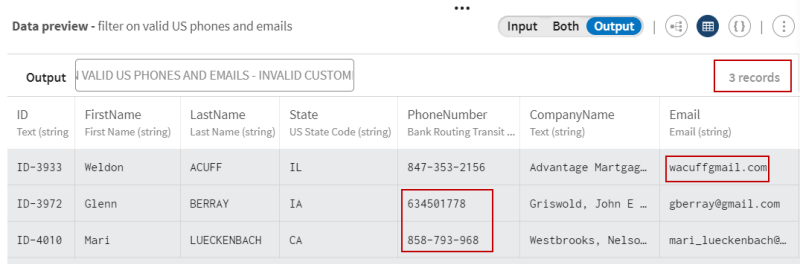
プロセッサーのプレビューに注目し、フィルタリング操作前後のデータを比較します: セマンティックタイプと一致させると、無効なメールアドレス値(メールアドレスの@記号が抜けています)が1つと無効な電話番号値(数字が抜けています)を含むレコードが2つあることがわかります。
-
Semantic filterプロセッサーにある
![[Doesn't match filter] (フィルターに一致しない)](/ja-JP/pipeline-designer-processors-guide/Cloud/Content/Resources/images/icon-plus-orange.png) ボタンをクリックし、[ADD DESTINATION] (デスティネーションを選択)項目をクリックして、リジェクトされたデータを保持するデータセットを選択します。無効な値を含むデータ。
ボタンをクリックし、[ADD DESTINATION] (デスティネーションを選択)項目をクリックして、リジェクトされたデータを保持するデータセットを選択します。無効な値を含むデータ。
タスクの結果
パイプラインは実行中となり、選択したセマンティックタイプに基づいてデータがフィルタリングされ、指定したデスティネーションに出力フローが送られます。
次のタスク
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。