
フィールドをハッシュしてデータを安全に比較
始める前に
-
ソースデータを保管するシステムへの接続が作成済みであること。
ここでは、Amazon S3接続を使用します。
-
ソースデータを保管するデータセットが追加済みであること。
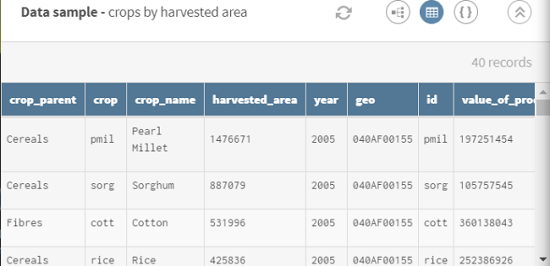
string-crops.csvファイルをダウンロードします。マリで収穫された作物に関するデータ(作物の種類、生産額、収穫面積など)を持つセットが含まれています。
-
接続および処理済みデータを保管する関連データセットも作成済みであること。
ここでは、同じS3バケットに保存されているデータセットを使用します。
手順
-
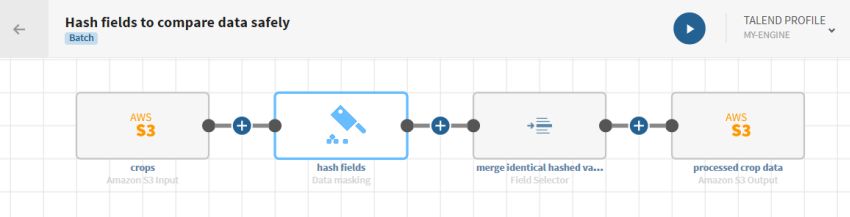
[ADD SOURCE] (ソースを追加)をクリックしてパネルを開きます。このパネルで、ソースデータ(この場合は2005年のマリにおける収穫作物に関するデータ)を選択できます。
例
-
 をクリックし、パイプラインにData hashingプロセッサーを追加します。設定パネルが開きます。
をクリックし、パイプラインにData hashingプロセッサーを追加します。設定パネルが開きます。
-
[Configuration] (設定)エリアで以下の操作を行います。
-
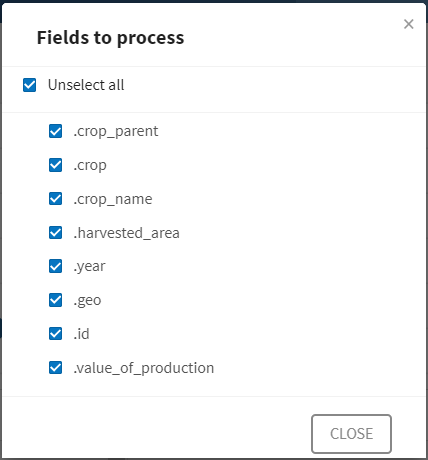
すべての値を一度にハッシュする場合は、[Fields to process] (処理するフィールド)リストの横にある
![[Open dialog] (ダイアログを開く)](/ja-JP/pipeline-designer-processors-guide/Cloud/Content/Resources/images/icon-open-dialog.png) アイコンをクリックします。
アイコンをクリックします。
-
すべての値を一度にハッシュする場合は、[Fields to process] (処理するフィールド)リストの横にある
-
[Save] (保存)をクリックして設定を保存します。
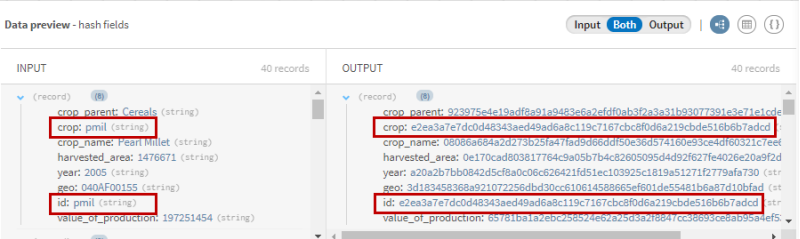
プロセッサーのプレビューに注目し、操作前のデータと結合後のデータを比較します。
これですべてのフィールドがハッシュおよびセキュア化されます。cropフィールドとidフィールドの出力値が同じになっていますが、これは元の値が両方のフィールドで同じであることを表します。
-
をクリックし、パイプラインにField selectorプロセッサーを追加します。設定パネルが開きます。
-
[Save] (保存)をクリックして設定を保存します。
プロセッサーのプレビューに注目し、操作前のデータと結合後のデータを比較します。

タスクの結果
パイプラインは実行中となり、データはハッシュされ、同一のフィールドは記述した条件に基づいてマージおよび再編成され、出力は指定したターゲットシステムに送信されます。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。