
テストケースを使ってSparkジョブをテスト
Sparkテストケースを完了するには、テストケースを使ってジョブとサービスをテストに説明されているのと同じ手順に従う必要があります。ただし、Sparkジョブには異なる専用のテストスケルトンがあることにご注意ください。
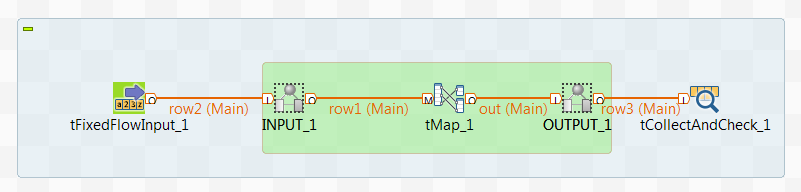
デフォルトでは、Sparkテストスケルトンには以下が含まれています。
-
1つ(または複数)のtFixedFlowInputコンポーネント(またはSpark Streamingジョブの場合はtBoundedStreamInput)。入力ファイルをロードするジョブ内の入力フローの数によります。
-
1つ(または複数)のSpark Streamingジョブ用tBoundedStreamInput。入力ファイルをロードするジョブ内の入力フローの数によります。
-
読み取り専用のINPUTおよびOUTPUTアイコン。テストする部分の最初と最後を示すために使用します。
-
1つ(または複数)のtCollectAndCheckコンポーネント。一時出力ファイルを参照ファイルと比較するためのジョブ内の出力フローの数によります。比較されたファイルペアが同一であればテストは成功、そうでなければ失敗と見なされます。
また、[Spark configuration] (Spark設定)タブでは[Local] (ローカル)モードがデフォルトで使用されます。入力フローと出力フローの数に応じて、入力ファイルと参照ファイルを指定するために、いくつかのコンテキスト変数が自動的に作成されます。また、tFixedFlowInputまたはtBoundedStreamInputの[Basic settings] (基本設定)タブで[Use context variable] (コンテキスト変数の使用)ラジオボタンが利用できます。これは自動的に選択され、新しいコンテキスト変数の1つが選択できるようになっています。
ジョブのテストケースを作成する前に、ジョブのすべてのコンポーネントが設定済みであることをご確認ください。
継続的インテグレーション、およびそれをTalendに実装する方法は、ソフトウェア開発ライフサイクル - ベストプラクティスガイドをご覧ください。
このページは役に立ちましたか?
このページまたはコンテンツに、タイポ、ステップの省略、技術的エラーなどの問題が見つかった場合は、お知らせください。改善に役立たせていただきます。