
Dédoublonnage d'entrées en utilisant des composants Map/Reduce
Le framework MapReduce est déprécié à partir de la version 7.3 de Talend. Utilisez des Jobs Talend pour Apache Spark afin d'accomplir vos tâches d'intégration.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Ce scénario s'applique uniquement aux produits Talend Platform avec Big Data et à Talend Data Fabric.
Ce scénario montre comment créer un Job Talend Map/Reduce afin de dédoublonner des entrées. En d'autres termes, ce scénario utilise des composants Map/Reduce afin de générer du code Map/Reduce et exécuter le Job dans Hadoop.
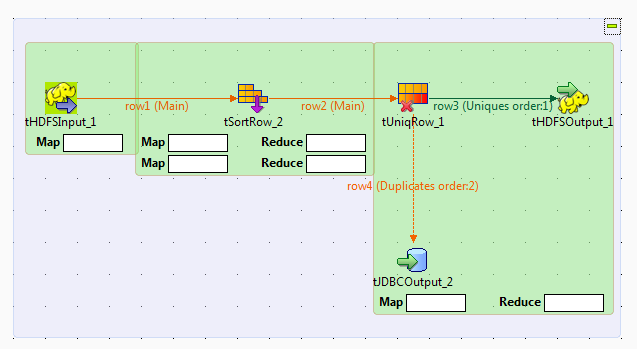
Notez que les composants Map/Reduce de Talend ne sont disponibles que pour les utilisateurs et utilisatrices ayant souscrit à une offre Big Data, et que ce scénario ne peut être reproduit qu'avec des composants Map/Reduce.
1;Harry;Ford;68;Albany
2;Franklin;Wilson;79;Juneau
3;Ulysses;Roosevelt;25;Harrisburg
4;Harry;Ford;48;Olympia
5;Martin;Reagan;75;Columbia
6;Woodrow;Roosevelt;63;Harrisburg
7;Grover;McKinley;98;Atlanta
8;John;Taft;93;Montpelier
9;Herbert;Johnson;85;Lincoln
10;Grover;McKinley;33;Lansing
Étant donné que le Studio Talend vous permet de convertir un Job Map/Reduce en Job Standard (non Map/Reduce), et vice-versa, vous pouvez convertir le scénario expliqué plus tôt afin de créer ce Job Map/Reduce. Ainsi, la plupart des composants utilisés peuvent garder leurs paramètres d'origine afin de réduire votre charge de travail pour la création de ce Job.
Avant de commencer à reproduire ce scénario, assurez-vous d'avoir les droits d'accès appropriés à la distribution Hadoop à utiliser. Procédez comme suit :
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – dites-nous comment nous améliorer !