
Crawling für mehrere Datensätze
Wenn Sie zahlreiche Datensätze aus derselben Quelle importieren müssen, brauchen Sie sie nicht einzeln manuell in Talend Cloud Data Inventory zu erstellen, sondern können einen Crawler einrichten, um eine komplette Asset-Liste in einem einzigen Vorgang abzurufen.
Durch das Crawling einer Verbindung können Sie ein umfangreiches Datenvolumen abrufen und Ihren Datenbestand wesentlich effizienter anreichern. Nach der Auswahl einer Verbindung können Sie den gesamten zugehörigen Inhalt bzw. einen Teil davon importieren, indem Sie Schnellsuche und Filter verwenden. Außerdem können Sie die Benutzer auswählen, die Zugriff auf die neu erstellten Datensätze erhalten sollen.
- Dynamic selection (Dynamische Auswahl) - Abrufen aller Tabellen, die einem bestimmten Filter entsprechen, ungeachtet des Inhalts Ihrer Datenquelle zum jeweiligen Zeitpunkt.
- Manual selection (Manuelle Auswahl) - Manuelle Auswahl der Tabellen zum Abrufen des aktuellen Status Ihrer Datenquelle.
Für das Crawling einer Verbindung für mehrere Datensätze sind die folgenden Voraussetzungen und Einschränkungen gegeben:
- Ihnen wurde in Talend Management Console die Rolle Dataset administrator (Datensatzadministrator) oder Dataset manager (Datensatzmanager) oder zumindest die Berechtigung Crawling - Add (Crawling - Hinzufügen) zugewiesen.
- Sie verwenden eine Remote Engine ab Version 2022-02.
- Sie können lediglich Daten über eine JDBC-Verbindung crawlen. Zudem kann für eine Verbindung jeweils nur ein einzelner Crawler erstellt werden.
Prozedur
-
Zur Erstellung eines Crawlers für eine Verbindung stehen Ihnen folgende Möglichkeiten zur Auswahl:
- Positionieren Sie den Mauszeiger auf Ihrer Verbindung in der Verbindungsliste, klicken Sie auf das Symbol Crawl connection (Verbindung crawlen) und anschließend auf die Schaltfläche Add crawler (Crawler hinzufügen).
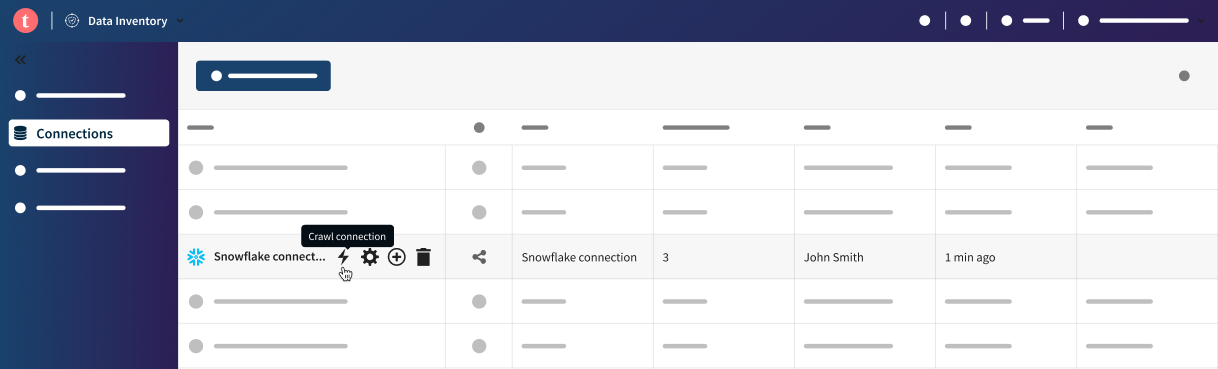
- Klicken Sie auf die Verbindung in der Verbindungsliste, wählen Sie die Registerkarte Crawler in der Schublade aus und klicken Sie auf Add crawler (Crawler hinzufügen).
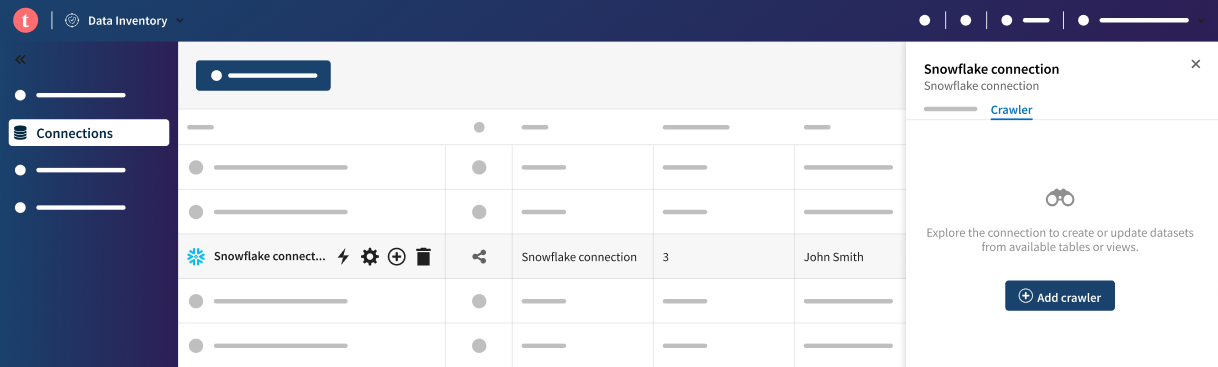
Daraufhin wird das Fenster der Crawler-Konfiguration geöffnet. - Positionieren Sie den Mauszeiger auf Ihrer Verbindung in der Verbindungsliste, klicken Sie auf das Symbol Crawl connection (Verbindung crawlen) und anschließend auf die Schaltfläche Add crawler (Crawler hinzufügen).
-
Klicken Sie auf Run (Ausführen).
Daraufhin wird im Hintergrund ein asynchroner Prozess gestartet, um die über die Verbindung ausgewählten Datensätze zu crawlen. Sie sind jetzt zur Verbindungsliste zurückgekehrt, die Registerkarte Crawler ist in der rechten Schublade geöffnet. Hier können Sie den Status der Datensatzerstellung sowie die Verfügbarkeit der Samples überwachen.
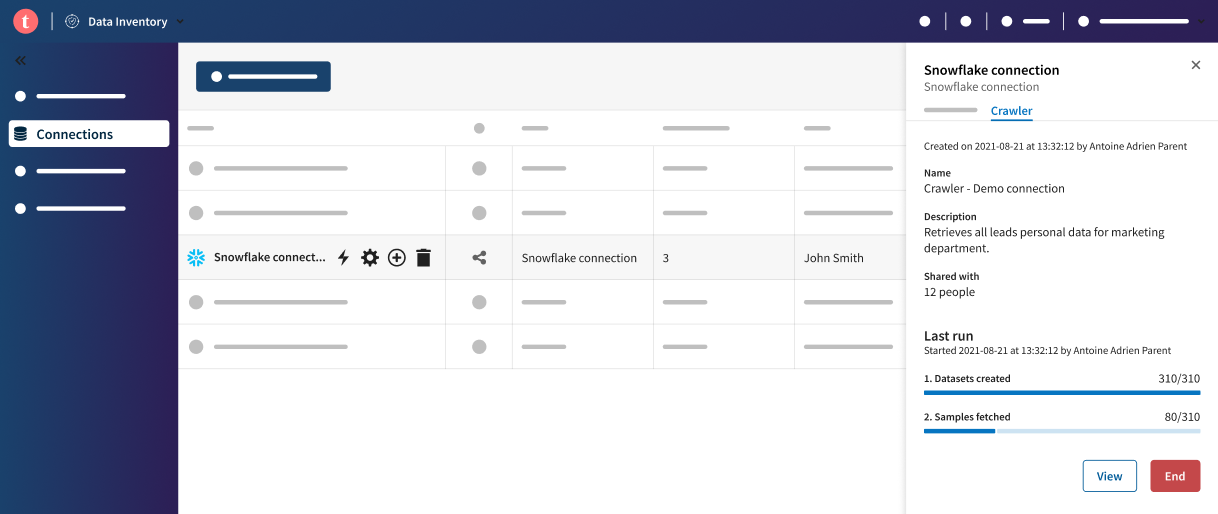 InformationshinweisAnmerkung: Wenn alle Samples abgerufen wurden, werden Datenqualität und Talend Trust Score™ für jeden gecrawlten Datensatz vollständig verarbeitet und sowohl in der Datensatzliste als auch in jeder Datensatzübersicht angezeigt. Wenn Sie einen der gecrawlten Datensätze bearbeiten möchten, bevor das entsprechende Sample zur Verfügung steht, können Sie den Datensatz manuell abrufen. Klicken Sie dazu auf Refresh sample (Sample aktualisieren) in der Ansicht des Datensatz-Samples.
InformationshinweisAnmerkung: Wenn alle Samples abgerufen wurden, werden Datenqualität und Talend Trust Score™ für jeden gecrawlten Datensatz vollständig verarbeitet und sowohl in der Datensatzliste als auch in jeder Datensatzübersicht angezeigt. Wenn Sie einen der gecrawlten Datensätze bearbeiten möchten, bevor das entsprechende Sample zur Verfügung steht, können Sie den Datensatz manuell abrufen. Klicken Sie dazu auf Refresh sample (Sample aktualisieren) in der Ansicht des Datensatz-Samples.
Ergebnisse
Nach dem Start der Ausführung des Crawlers können Sie die Crawler-Konfiguration nicht mehr bearbeiten. Nachdem der Crawler angehalten wurde oder fertig ist, können Sie die Tabellenauswahl, den Namen und die Beschreibung des Crawlers bearbeiten. Die Freigabeeinstellungen können aber nicht bearbeitet werden. Um die Verbindung mit anderen Freigabeeinstellungen erneut zu crawlen, löschen Sie den Crawler und erstellen Sie einen neuen.
Sie können einen Crawler-Namen als Facette in der Datenbanksuche verwenden, um alle mit dem betreffenden Crawler verknüpften Datensätze anzuzeigen.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!