
Auffinden von Kundenfirmen nach Leads
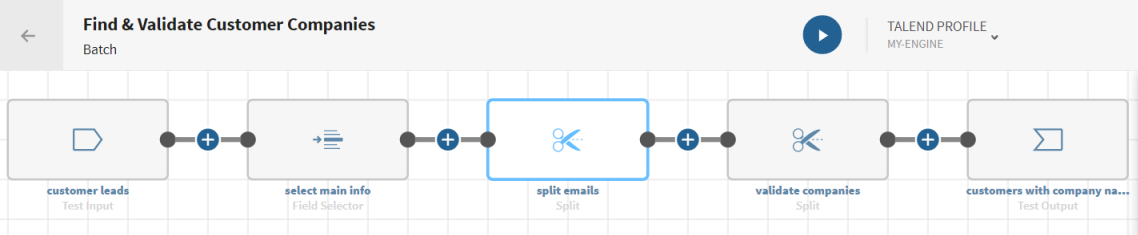
Vorbereitungen
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
Laden Sie folgende Datei herunter und extrahieren Sie sie: split-leads.zip. Sie enthält einen Datensatz mit einer Liste der Kunden-Leads, u. a. Vornamen, Nachnamen, E-Mail-Adressen, Adressen usw.
-
Sie haben außerdem die Verbindung und den zugehörigen Datensatz erstellt, der die verarbeiteten Daten aufnehmen soll.
In diesem Beispiel eine über eine Testverbindung gespeicherte Datei.
Prozedur
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Field Selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Field Selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf Save (Speichern), um die Konfiguration zu speichern.
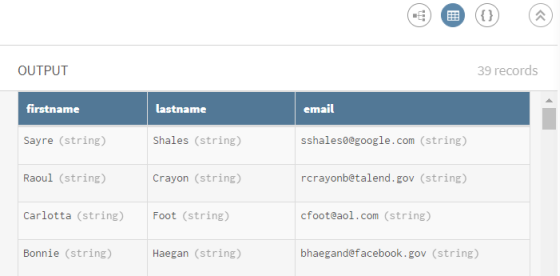
(Optional) Sehen Sie sich die Vorschau des Prozessors an, um die Daten vor der Umstrukturierung mit denjenigen danach zu vergleichen.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Split (Untergliedern) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen weiteren Prozessor vom Typ Split (Untergliedern) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
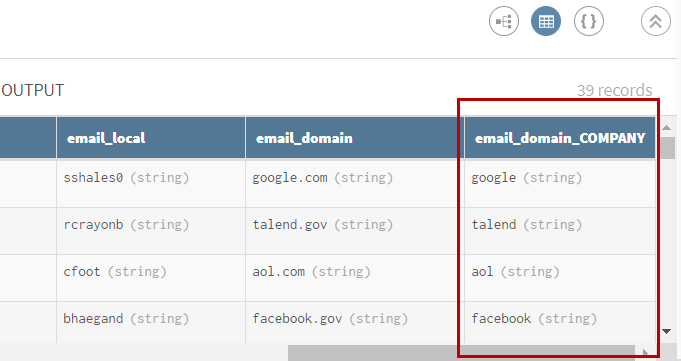
(Optional) Sehen Sie sich die Vorschau des Prozessors vom Typ Split (Untergliedern) an, um zu prüfen, wie Ihre Daten nach der Extraktion aussehen.
Example
Ergebnisse
Ihre Pipeline wird ausgeführt, die Lead-Daten werden verarbeitet, die Kundenfirmen mit den semantischen Typen der Firmen verglichen und der Ausgabe-Flow wird an das von Ihnen angegebene Zielsystem gesendet.
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!