
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Unterstützung für HPE Ezmeral Runtime Enterprise 5.4 unter Kubernetes mit Spark 3.1.x | Sie können Ihre Spark Batch- und Streaming-Jobs jetzt unter Kubernetes mit Livy und Datatap unter Rückgriff auf Spark Universal mit Spark 3.1.x ausführen.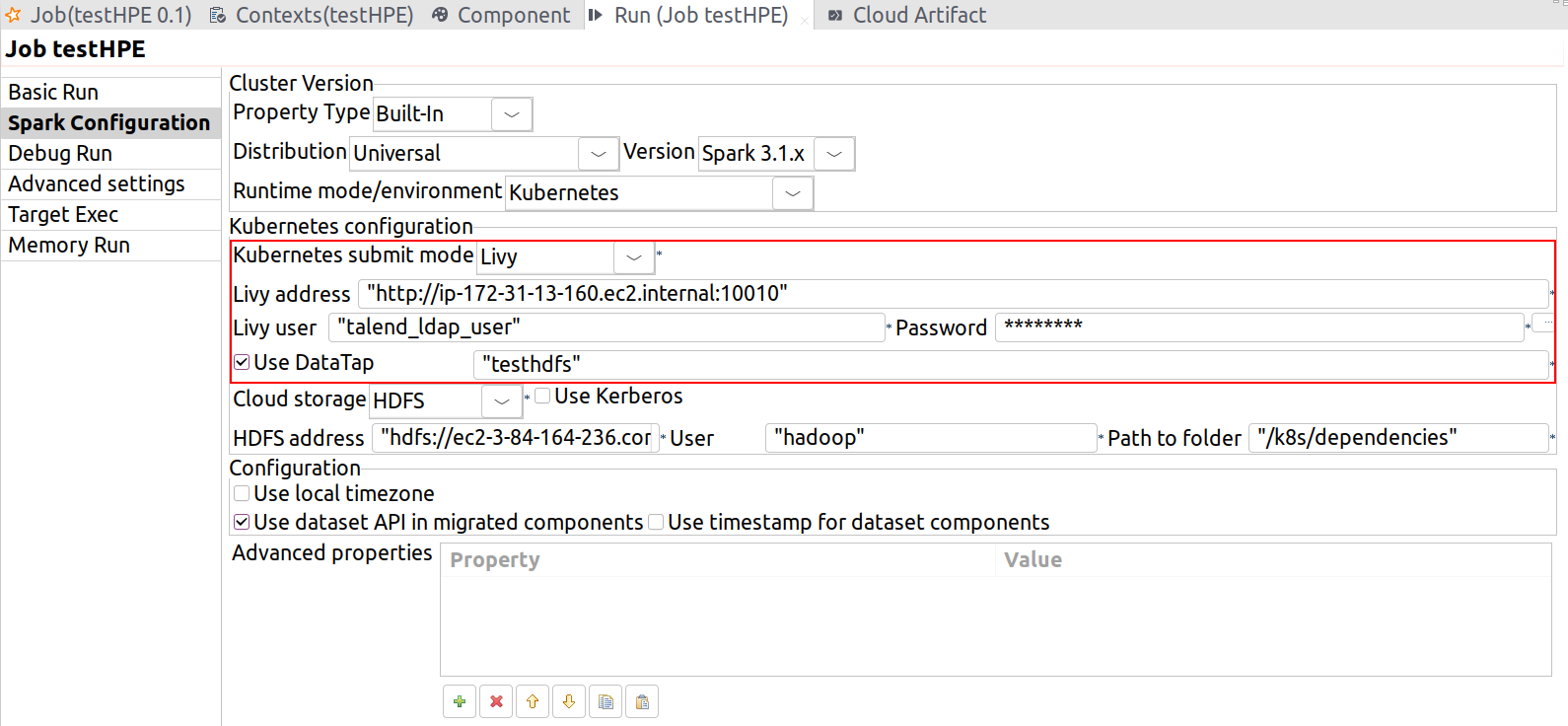
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Databricks 12.x Runtime mit Spark Universal 3.3.x | Sie können Ihre Spark Batch- und Streaming-Jobs jetzt in universellen und jobbasierten Clustern in Google Cloud Platform (GCP), AWS und Azure unter Verwendung von Spark Universal mit Spark 3.3.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Studio Talend mit Databricks 12.x kompatibel. 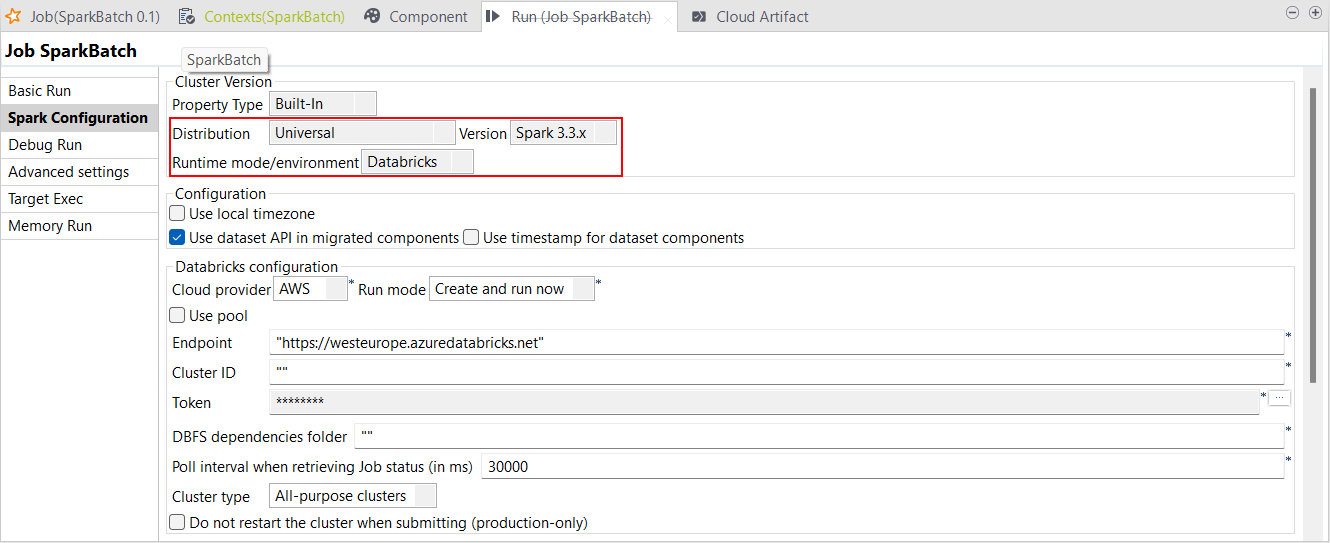
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für Amazon EMR ab 6.6.0 und 6.7.0 mit Spark Universal 3.2.x | Sie können Ihre Spark-Jobs jetzt in einem Amazon EMR-Cluster unter Rückgriff auf Spark Universal mit Spark 3.3.x im Yarn-Cluster-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Studio Talend mit den Versionen 6.8.0 und 6.9.0 von Amazon EMR kompatibel. Mit der Betaversion dieser Funktion sind die folgenden bekannten Probleme gegeben, für die ein Workaround existiert:
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für MongoDB v4+ für Spark Streaming ab Version 3.1 | Studio Talend bietet jetzt Unterstützung für MongoDB v4+ mit Spark ab Version 3.1 für die folgenden Komponenten in Ihren Spark Streaming-Jobs unter Verwendung von Dataset:
Mit der Betaversion dieser Funktion muss in der Dropdown-Liste DB Version (DB-Version) die MongoDB-Version MongoDB 3.2+ ausgewählt werden. |
Alle abonnementbasierte Produkte von Talend mit Big Data |
Hat diese Seite Ihnen geholfen?
Wenn Sie Probleme mit dieser Seite oder ihren Inhalten feststellen – einen Tippfehler, einen fehlenden Schritt oder einen technischen Fehler –, teilen Sie uns bitte mit, wie wir uns verbessern können!