
Neue Funktionen
Freigegebene Funktionen
| Funktion | Beschreibung |
|---|---|
| Möglichkeit zum Import von transitiven Abhängigkeiten als Bibliotheken für globale Routinen, globale Beans, benutzerdefinierte Routine-JARs und benutzerdefinierte Bean-JARs | Bei der Bearbeitung von Bibliotheken für globale Routinen, globale Beans, benutzerdefinierte Routine-Jars oder benutzerdefinierte Bean-Jars steht im Dialogfeld Module (Modul) jetzt ein neues Kontrollkästchen Add transitive dependencies (Transitive Abhängigkeiten hinzufügen) bereit. Damit können Sie transitive Abhängigkeiten einer Bibliotheksdatei oder POM-Datei importieren.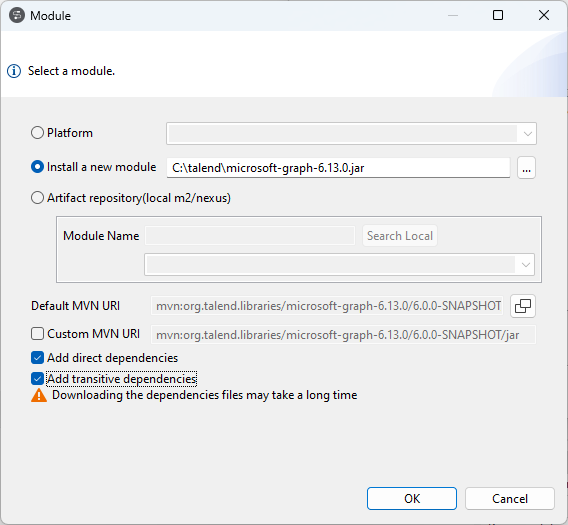 Weitere Informationen finden Sie unter Bearbeiten benutzerdefinierten Routine-Bibliotheken und Bearbeiten von Bean-Bibliotheken. |
Anwendungsintegration
| Funktion | Beschreibung |
|---|---|
| Neue cJSLT-Komponente in Routen | Die neue cJSLT-Komponente ermöglicht es Ihnen, JSON-Nachrichten mithilfe von JSLT-Vorlagen umzuwandeln.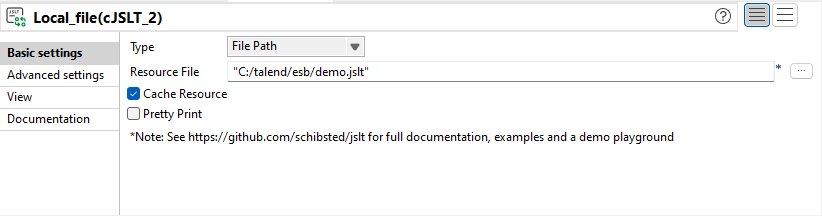 |
Big Data
| Funktion | Beschreibung |
|---|---|
| Unterstützung für Hive 3 in Standard-Aufträgen | Sie können nun Ihre Standard-Jobs mithilfe von Hive 3 ausführen. Sie können es in der Ansicht Basic settings (Basiseinstellungen) von Hive-Komponenten konfigurieren. Mit dieser Funktion ändert sich der Eigenschaftenname von Hive server (Hive-Server) in Hive version (Hive-Version). 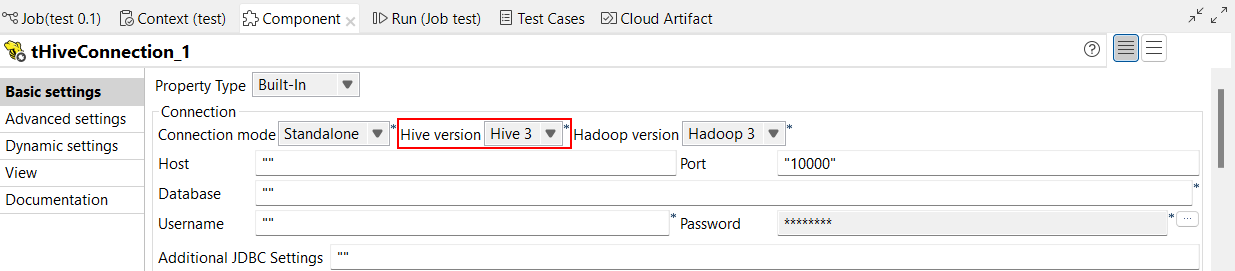 |
| Unterstützung für CDP Public Cloud Data Hub 7.2.18 mit Spark Universal 3.3.x | Sie können Ihre Spark-Batch- und Spark-Streaming-Aufträge in CDP Public Cloud Data Hub mit AWS, Azure und GCP jetzt mithilfe von Spark Universal mit Spark 3.3.x ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Wenn Sie diesen Modus auswählen, ist Talend Studio mit Version 7.2.18 von CDP Public Cloud Data Hub kompatibel. Mit dieser Funktion wird die Knox-Authentifizierung unterstützt. HBase wird allerdings nicht unterstützt. Weitere Informationen zu Spark Universal finden Sie unter Unterstützung von Spark Universal für Hadoop-Distributionen in Talend Studio. |
Kontinuierliche Integration (CI = Continuous Integration)
| Funktion | Beschreibung |
|---|---|
| Talend CI Builder aktualisiert auf Version 8.0.18 | Talend CI Builder wurde von der Version 8.0.17 auf die Version 8.0.18 aktualisiert. Verwenden Sie ab dieser monatlichen Version Talend CI Builder 8.0.18 sowie Maven in der Version 3.6.3 oder höher in Ihren CI-Befehlen (Continuous Integration: Kontinuierliche Integration) oder Pipeline-Skripten bis zur Veröffentlichung einer neuen Version von Talend CI Builder. |
Datenintegration
| Funktion | Beschreibung |
|---|---|
|
Unterstützung für Kontoauthentifizierungsmethode in tFTPConnection in Standard-Aufträgen |
Der Authentifizierungstyp 'Passwort und Konto' wurde zur tFTPConnection-Komponente hinzugefügt und ermöglicht Ihnen, auf einen FTP-Server mithilfe des Kontonamens zuzugreifen, der mit einem spezifischen Benutzer verknüpft ist. |
|
Unterstützung für Azure Key Vault für Spaltenverschlüsselung und -entschlüsselung in MSSql-Komponenten in Standard-Aufträgen |
Die Option 'Enable always encrypted' (Immer verschlüsselt aktivieren) wurde zu den MSSql-Komponenten hinzugefügt und ermöglicht es Ihnen, Ihre Daten mithilfe von Azure Key Vault zu verschlüsseln und zu schützen, um geheime Schlüssel zu speichern. |
|
Unterstützung für JSON-Nutzlastnormalisierung in tHTTPClient in Standard-Aufträgen |
Die Option 'Normalize the JSON HTTP response' (JSON-HTTP-Antwort normalisieren) wurde zur tHTTPClient-Komponente und zum HTTP-Client-Cloud-Konnektor hinzugefügt und ermöglicht es Ihnen, Inkonsistenzen in JSON-Nutzlasten zu normalisieren, damit diese Dokumente korrekt analysiert werden können. |
Datenqualität
| Funktion | Beschreibung |
|---|---|
| tMatchGroup für Spark Batch | Sie können nun die tMatchGroup-Komponente im Spark Batch-Job-Framework verwenden. Diese Komponente erstellt Gruppen ähnlicher Datensätze in beliebigen Quelldaten einschließlich großer Datenvolumina durch Verwendung einer oder mehrerer Match Regeln. Weitere Informationen finden Sie unter tMatchGroup. |