
Dynamically selecting a preparation at runtime according to the input
This scenario applies to all Talend products.
For more technologies supported by Talend, see Talend components.
The tDataprepRun component allows you to reuse an existing preparation made in Talend Data Preparation, directly in a data integration, Spark Batch or Spark Streaming Job. In other words, you can operationalize the process of applying a preparation to input data with the same model.
By default, the tDataprepRun component retrieves preparations using their technical id. However, the dynamic preparation selection feature allows you to call a preparation via its path in Talend Data Preparation. Through the use of the Dynamic preparation selection check box and some variables, it is then possible to dynamically select a preparation at runtime, according to runtime data or metadata.
In case you wanted to operationalize preparations in a Talend Job using the regular preparation selection properties, you would actually need several Jobs: one for each preparation to apply on a specific dataset. By retrieving the correct preparation according to the input file name, you will be able to dynamically run more than one preparation on your source data, in a single Job.
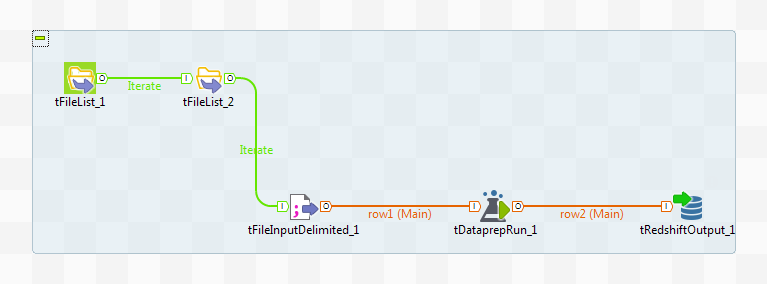
The following scenario creates a Job that:
- Scans the content of a folder containing several datasets
- Creates a dynamic path to your CSV files
- Dynamically retrieves the preparations according to the input file name and applies them on the data
- Outputs the prepared data into a Redshift database
In this example, .csv datasets with data from two of your clients are locally stored in a folder called customers_files. Each of your clients datasets have their specific naming convention and are stored in dedicated sub folders. All the datasets in the customers_files folder have identical schemas, or data model.

A customers folder has also been created in Talend Data Preparation, containing two preparations. These two distinct preparation are each aimed at cleaning data from your two different customers.
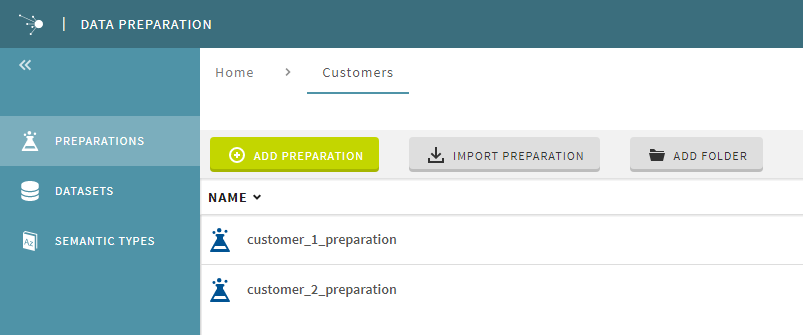
The purpose of customer_1_preparation for example is to isolate a certain type of email addresses, while customer_2_preparation aims at cleansing invalid values and formatting the data. In this example, the preparations names are based on the two sub folders names customer_1 and customer_2, with _preparation as suffix.
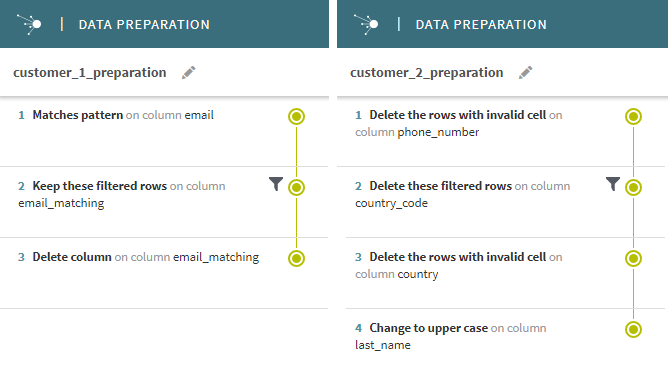
Just like the input schema that all four dataset have in common, all of your output data must also share the same model. For this reason, you cannot have one preparation that modifies the schema by adding a column for example, while the other does not.
By following this scenario, a single Job will allow you to use the appropriate preparation, depending on whether the dataset extracted from the local customers_files folder belongs to customer 1 or customer 2.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!