
How to handle the dynamic headers found in W3C Extended Log Format using tJavaFlex
| Version | All currently supported enterprise and platform versions (Data Integration Batch Jobs) |
Environment
- This article was written using Talend Studio for Data Integration 6.3.1 (Enterprise). Hence, the jobs attached will only import in Talend version 6.3.1 and above.
- The tJavaFlex component is available in all currently supported versions of Talend Studio.
W3C Extended Log Format
According to W3C, the extended log format contains two types of lines, directives (header) and entries (data). Each entry line contains a list of fields, while the directives contain metadata about the log itself. The Fields directive specifically holds the list of fields that we will need to be parsed to read the log data in the line entries.
The following is an example log. Notice the third line for the Fields directive. Note that the fields in a W3C Log is space separated.
#Version: 1.0
#Date: 2001-05-02 17:42:15
#Fields: time cs-method cs-uri-stem sc-status cs-version
17:42:15 GET /default.htm 200 HTTP/1.0
17:42:15 GET /default.htm 200 HTTP/1.0
Solution
Since the field and values are space separated, it is possible to read the above file with a tFileInputDelimited component. We will configure the component to skip the first 3 lines, and read the line entries with a space character as the fields delimiter. However, the challenge of this solution is that it does not adapt dynamically to make sure the correct columns are being mapped to the right fields if the administrator changes the order or names of the fields being outputted in the log. Our objective is to map the correct fields always irrespective of how the IT administrator changes the order or name of the fields being outputted by the log. This is why we are going to design a solution to read the known fields and map them, while ignoring new and unknown fields. Existing fields which are removed from the definition will send out null values in our job.
Our solution is to use tJavaFlex to correctly map the fields. We will:
- Find the Fields directive, read in the field list
- Read the log entries line by line
- Parse the log entries
- Map the fields from the log entries to the fields defined in our schema. We will ignore new, unknown and missing fields. The solution will also perform any required data type parsing
How tJavaFlex Works
The tJavaFlex enables a developer to enter personalized code in order to integrate it in a Talend data integration job. With tJavaFlex , you can enter the three java-code parts (start, main and end) that constitute a component to perform a desired operation. By coding the three parts (start, main and end) correctly, Talend ensures that the logic behaves as expected within the data flow of a subJob. Please refer to the documentation of the component to learn more about the tJavaFlex.
Create the Job
Create a Job as shown below with the tJavaFlex and tLogRow components.

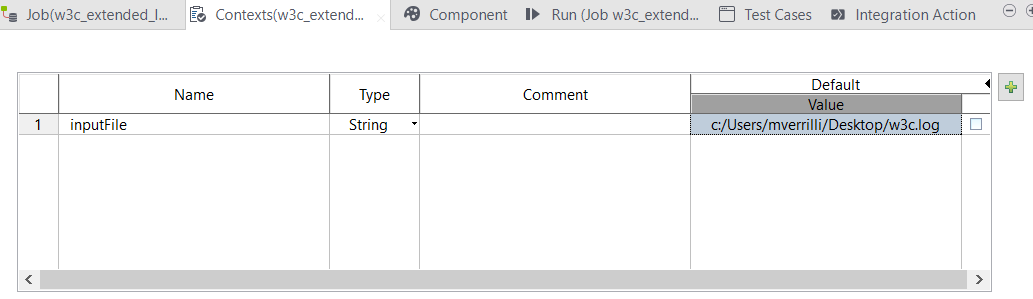
Create a new context variable inputFile to reference the path of the input file. We will use the context variable in the tJavaFlex component code.
Define the schema
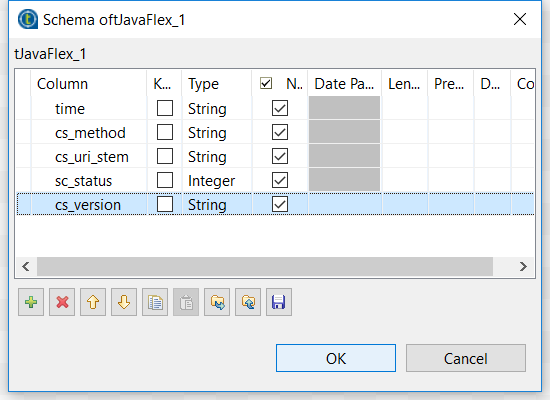
For our example, we will be interested in these fields: time cs-method cs-uri-stem sc-status cs-version . Since the schema field names much conform to Talend standards and cannot contain a dash in the Schema Editor in Talend, we will simply use an underscore in place of the dash. The name does not need to match as the mapping will occur in the Main section of the tJavaFlex component. Note that we are mapping only the fields we want to extract from the log entries to keep our logic optimised. This is a best practice when designing data integration jobs. We only manipulate and load data we need in memory.
Configure the tJavaFlex Component
First, we will define the Start Code. Comments inline will explain the procedure in more detail, however do note the use of the context variable inputFile for the file path.
To summarize:
- Declare variables
- Open the file using a BufferedReader
- Scan the directives for Fields and parse the list into an array
- Start the loop to process data rows
Start Code
// In order to add new fields not currently supported,
// simply add the field to this component's schema,
// then at the switch statement in the main code,
// add the relevant mapping and data type conversion
// if required.
// input file is set via context variable
String file = context.inputFile;
// Raw line from file before being parsed
String line = "";
// Split line variable for parsed data
String[] parts;
// List of fields
String[] fieldList = {};
// lineCount to assist in case a specific line causea an exception
Long lineCount = new Long(0);
// errorLineCount to report a summary of the number of rows rejected due to errors
Long errorLineCount = new Long(0);
// Read the file and fill out the field list.
try (BufferedReader br = new BufferedReader(new FileReader(file)))
{
while ((line = br.readLine()) != null) {
lineCount++; // process the line.
if ( line.startsWith("#") ) {
System.out.println(line);
// If the fields directive is found, parse fields to an array
if ( line.startsWith("#Fields: ") ) {
fieldList = line.substring(9).split(" ");
break;
}
}
else {
// throw error to abort
throw new Exception("Field list not detected.");
}
}
// Process remaining file as data lines
while ((line = br.readLine()) != null) {
Next, we will process each row in the Main Code. Notice the switch statement's support
for each required field: time cs-method cs-uri-stem sc-status
cs-version.Main Code
lineCount++;
// Skip directives
if ( line.startsWith("#") ) {
continue;
}
try {
// parse the line
parts = line.split(" ");
// initialize new row
row1 = new row1Struct();
// Populate each field by position
for( int ii = 0; ii < fieldList.length; ii++) {
switch ( fieldList[ii] ) {
case "time" :
row1.time = parts[ii];
break;
case "sc-status" :
row1.sc_status = Integer.parseInt(parts[ii]);
break;
case "cs-method" :
row1.cs_method = parts[ii];
break;
case "cs-uri-stem" :
row1.cs_uri_stem = parts[ii];
break;
case "cs-version" :
row1.cs_version = parts[ii];
break;
default:
log.warn("Unhandled field encountered [" + fieldList[ii] + "].");
System.out.println("Unhandled field encountered [" + fieldList[ii] + "].");
}
}
} catch (java.lang.Exception e) {
//output exception for each log entry that causes an issue and continue to read next line
log.warn("tJavaFlex_1 [Line " + lineCount + "] " + e.getMessage());
System.err.println(e.getMessage());
errorLineCount++;
continue;
}
Now we will close off the data processing loop in the End Code section. Here we will also take the opportunity to print out some useful statistics to the log, warn about rejected rows, etc.
End Code
}
}
log.info("tJavaFlex_1 - " + lineCount + " rows processed.");
if (errorLineCount > 0) {
log.warn("tJavaFlex_1 - " + errorLineCount + " rows rejected.");
}
Finally, we need to add the required imports to the Advanced Settings Import section for the libs used.
Imports
import java.io.BufferedReader; import java.io.FileReader;
Running the job
Running the Job will output the header to the log (due to the println statements) along with the tLogRow output of each row. To see the additional logging data, you can set the Advanced Settings on the Run tab: log4jLevel => Info .
Starting Job w3c_extended_log_test at 17:45 10/02/2017.
[INFO ]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - TalendJob:
'w3c_extended_log_test' - Start.
[statistics] connecting to socket on port 3935
[statistics] connected
#Version: 1.0
#Date: 2001-05-02 17:42:15
#Fields: time cs-method cs-uri-stem sc-status cs-version
[INFO ]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Content of row 1:
17:42:15|GET|/default.htm|200|HTTP/1.0
17:42:15|GET|/default.htm|200|HTTP/1.0
[INFO
]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Content of row 2:
17:42:15|GET|/default.htm|200|HTTP/1.0
17:42:15|GET|/default.htm|200|HTTP/1.0
[INFO
]: sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tJavaFlex_1 - 5 rows
processed.
[INFO ]:
sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - tLogRow_1 - Printed row count:
2.
[statistics]
disconnected
[INFO ]:
sandbox.w3c_extended_log_test_0_1.w3c_extended_log_test - TalendJob: 'w3c_extended_log_test'
- Done.
Job w3c_extended_log_test ended at 17:45
10/02/2017. [exit code=0]Conclusion
Using the tJavaFlex component is a powerful feature within Talend allowing a wide range of extensibility. This example shows a method which allows a degree of flexibility in the incoming file formats. This single tJavaFlex implementation can handle incoming data in a variety of formats, including the addition of new fields, transposition of fields, and missing fields with a predictable result.
For more information, see tJavaFlex and Extended Log File Format.Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!