
Extracting the hashtag field from the raw Tweet data
Procedure
-
Double-click tExtractJSONFields to open its Component view.
 As you can read from https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags, the raw Tweet data uses the JSON format.
As you can read from https://dev.twitter.com/overview/api/entities-in-twitter-objects#hashtags, the raw Tweet data uses the JSON format. -
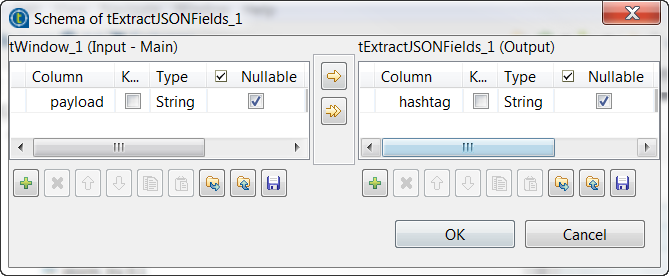
Click the [...] button next to Edit
schema to open the schema editor.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!