
tMap lookup models
To help you select the most adapted model according to your needs, this article details each model.
Three types of lookup loading models are provided suiting various types of business requirement:- Load once
- Reload at each row
- Reload at each row (cache)
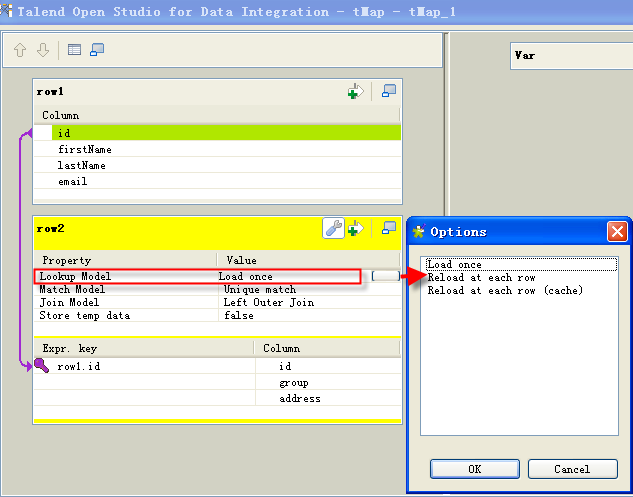
When implementing a join (including Inner Join and Left Outer Join) in a tMap between different data sources, there is always only one main flow and one or more lookup flows connected to the tMap . All the records of the lookup flow need to be loaded before processing each record of the main flow.
DescriptionLoad once: before processing each record of the main flow, this option loads once (and only once) all the records from the lookup flow either in the memory or in a local file in case the Store temp data option is set to true. This is the default setting for join and the best option if you have a large set of records in the main flow to be processed using a join to the lookup flow.
Reload at each row: all the records of the lookup flow are loaded again for each record of the main flow. Generally, this option increases the Job execution time due to the repeated loading of the lookup flow for each main flow record. However, this option should preferred in the following two situations:
- The lookup data flow is constantly updated and you want to load the newest lookup data for each record of main flow in order to get the new data after the join execution.
- You have less rows in your main flow and have a large data set that comes from a database table in the lookup flow. It might cause an OutOfMemory exception if you use the Load once option. In this situation, the Reload at each row option will be considered.
The procedure in the following section explains how to use the Reload at each row model.
Reload at each row (cache): this model functions like the Reload at each row model, all the records of the lookup flow are loaded again for each record of the main flow. However, this model can't be used with Store temp data on disk option. The lookup data are cached in memory, and when a new loading occurs, only the records that do not already exist in the cache will be loaded, in order to avoid loading the same records twice.
ProcedureThis procedure explains how to use the Reload at each row model. To gain in processing performance, it is recommended to use global variables in order to filter the main data flow and only process what needs to be processed.
-
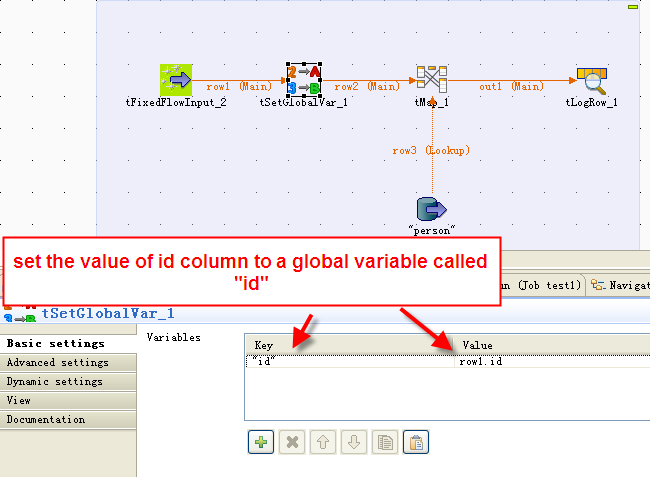
Set the value of one column of the main flow to a global variable ( tSetGlobalVar component), then use this variable in a WHERE condition in the lookup query, in order to only load the matched data from the table based on one or more values of the main flow, rather than loading the entire data.
-
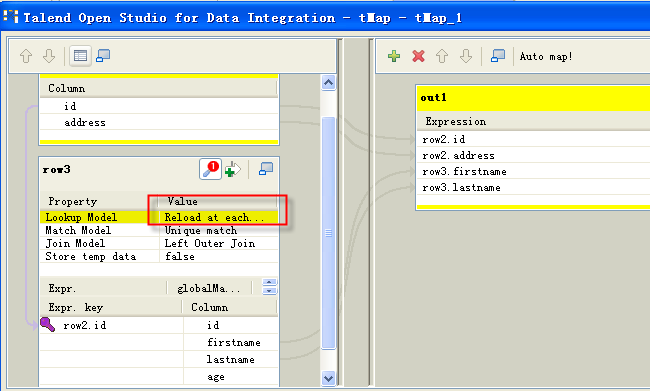
In the tMap component, select the Reload at each row model for the Lookup Model column:
-
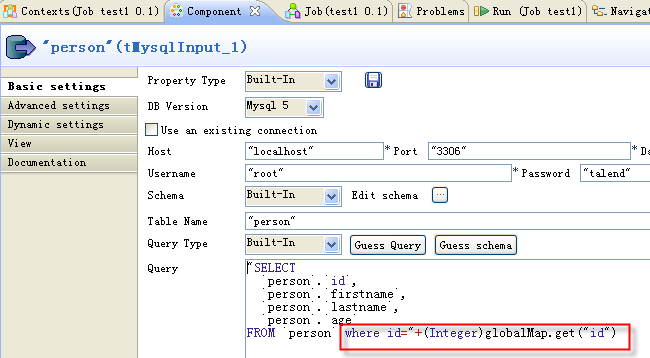
Use the global variable you have set in Step 1, in the lookup query to only load the matched data from the table.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!