
Saving and executing the Job
Procedure
-
Execute the Job by pressing F6 or
clicking Run on the Run tab.
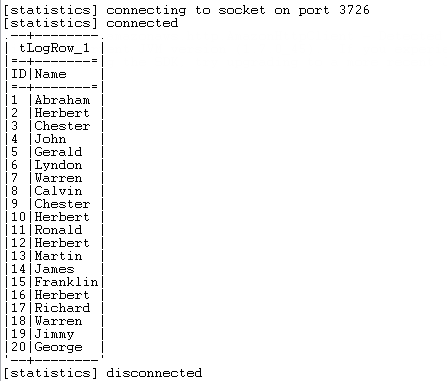
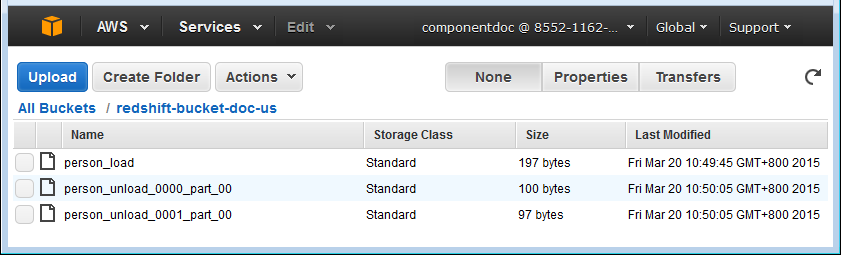
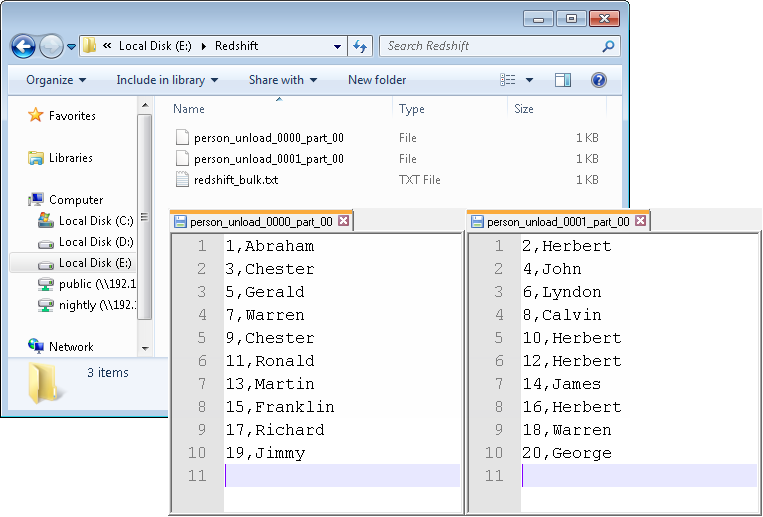 As shown above, the generated data is written into the local file redshift_bulk.txt, the file is uploaded on S3 with the new name person_load, and then the data is loaded from the file on S3 to the table person in Redshift and displayed on the console. After that, the data is unloaded from the table person in Redshift to two files person_unload_0000_part_00 and person_unload_0001_part_00 on S3 per slice of the Redshift cluster, and finally the unloaded files on S3 are listed and retrieved in the local folder.
As shown above, the generated data is written into the local file redshift_bulk.txt, the file is uploaded on S3 with the new name person_load, and then the data is loaded from the file on S3 to the table person in Redshift and displayed on the console. After that, the data is unloaded from the table person in Redshift to two files person_unload_0000_part_00 and person_unload_0001_part_00 on S3 per slice of the Redshift cluster, and finally the unloaded files on S3 are listed and retrieved in the local folder.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!