
Configuring the duplicate data
Procedure
-
Double-click tDuplicateRow to display the
Basic settings view and define the
component properties.

-
Click the Edit schema button to view the
input and output columns and do any modifications in the output schema, if
needed.
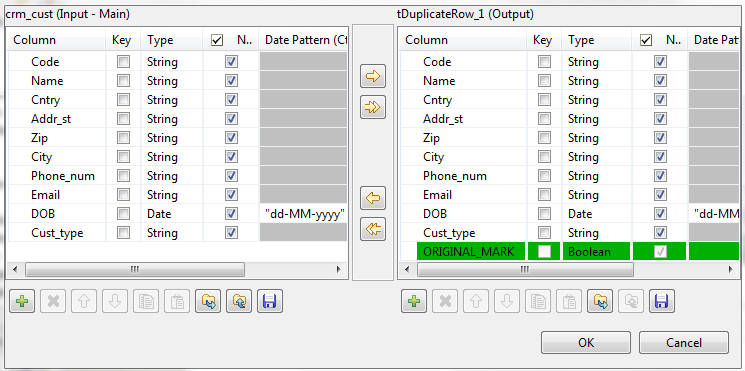 The output schema of this component contains one read-only column, ORIGINAL_MARK. This column identifies, by true or false, if the record is an original or a duplicate record. There is only one original record per group of duplicates.
The output schema of this component contains one read-only column, ORIGINAL_MARK. This column identifies, by true or false, if the record is an original or a duplicate record. There is only one original record per group of duplicates.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!