
Configuring the grouping of the output data
Procedure
-
Click the tMatchGroup
component, and then in its basic settings click the
Edit schema
button to view the input and output columns and do
any modifications in the output schema, if
needed.
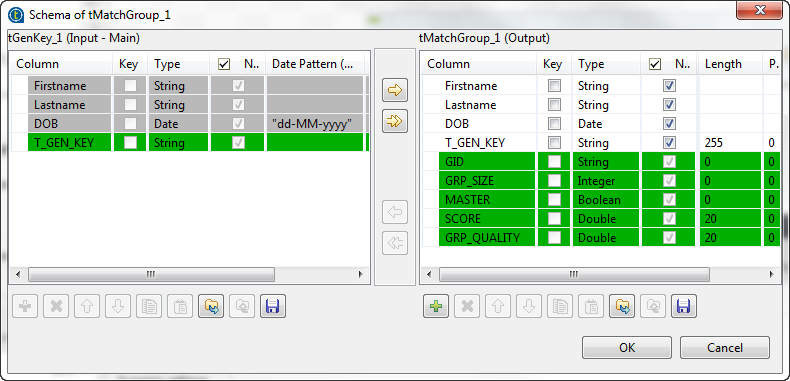 In the output schema of this component, there are output standard columns that are read-only. For more information, see tMatchGroup Standard properties.
In the output schema of this component, there are output standard columns that are read-only. For more information, see tMatchGroup Standard properties. -
Double-click the tMatchGroup component to
display its Configuration Wizard and define the
component properties.
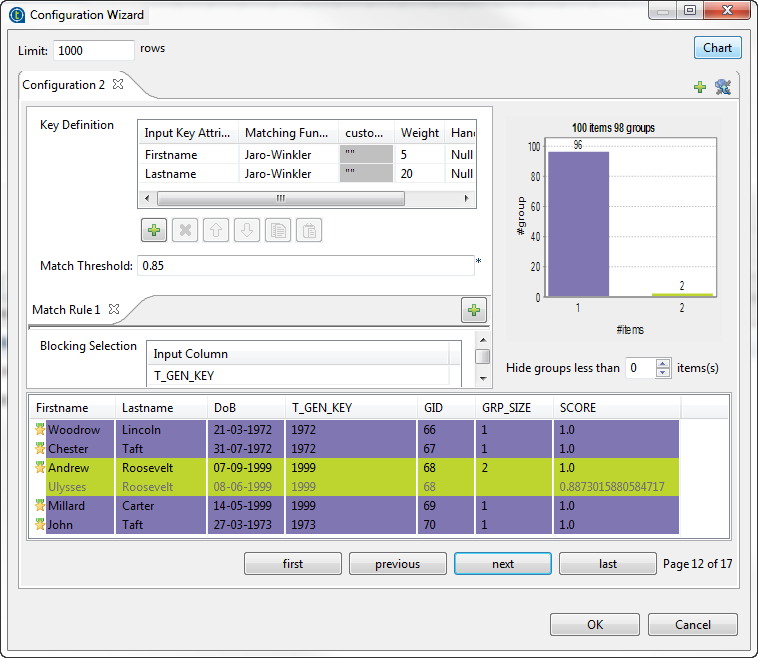 If you want to add a fixed output column, MATCHING_DISTANCES, which gives the details of the distance between each column, click the Advanced settings tab and select the Output distance details check box. For more information, see tMatchGroup Standard properties.
If you want to add a fixed output column, MATCHING_DISTANCES, which gives the details of the distance between each column, click the Advanced settings tab and select the Output distance details check box. For more information, see tMatchGroup Standard properties.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!