
Scanning data from Kudu
Procedure
-
Double-click tKuduInput to open its
Component view.
Example
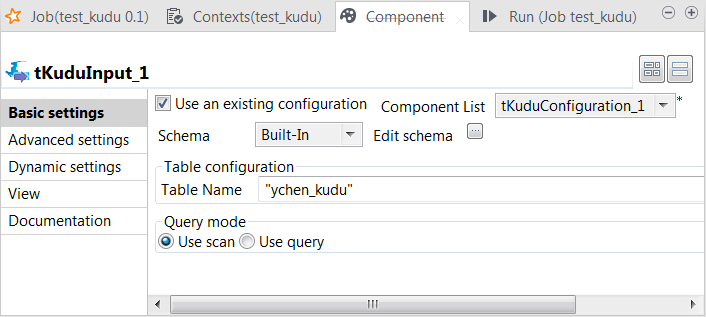
-
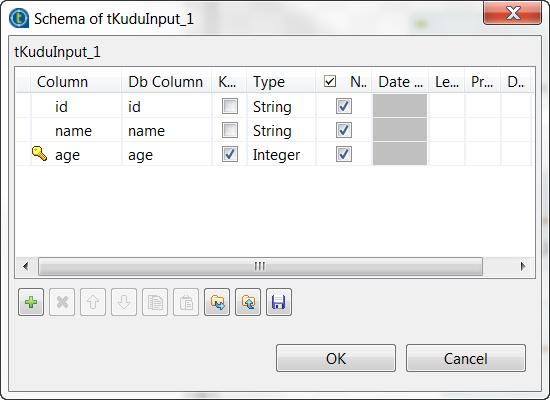
Click the [+] button to add the schema columns for
output as shown in this image.
Example
Results
Once done, in the console of the Run view, you can check the data read from the Kudu table.
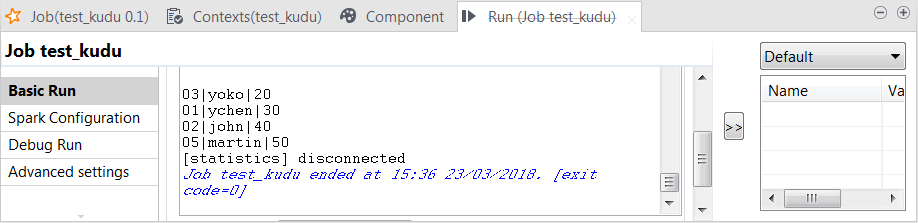
The record 04;tom;60 is not written in the table because it is out of the partition boundaries.
In the real-world practice, upon the success of the execution, you can deploy and launch your Job on a Talend JobServer if you have one.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!