
Reading the sample candidate data
Procedure
-
Double-click tFixedFlowInput to open its Component view.
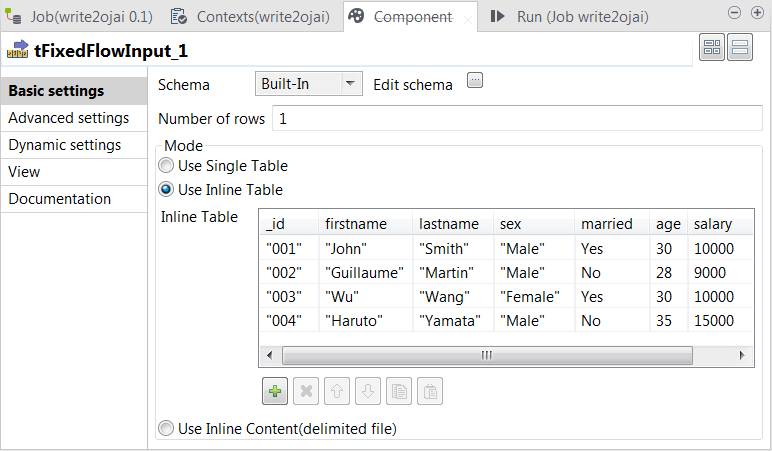
-
Click the [...] button to open the schema editor.
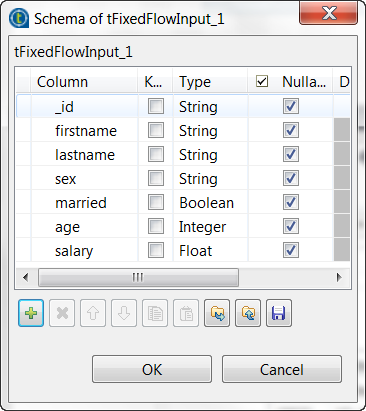
- The _id column exists already because this column was retrieved from tMapROjaiOutput in the previous steps to provide the technical IDs of the documents to be stored in a MapR Ojai database. This column is required by tMapROjaiOutput.
- Click the [+] button to add the other columns and rename them to firstname, lastname, sex, married, age and salary, respectively. The type of the married column should be Boolean, the type of the age column Integer and the salary column Float.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!