
Processing Parquet data using Snowflake components
This scenario shows the way to load data from a Parquet file into a Snowflake table and to retrieve the data from the Snowflake table.
For more technologies supported by Talend, see Talend components.
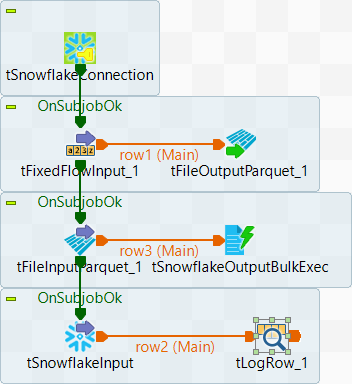
The Job in this scenario comprises four subJobs. The first subJob establishes a connection to Snowflake; the second subJob writes data to a Parquet file and stores the file on the local machine; the third subJob retrieves data from the Parquet file and upload the data to a Snowflake table; the fourth subJob retrieves data from the table which the data is uploaded to and display the data on the console. The following shows the Job used in this scenario.
This scenario assumes that you have the credential information and permission to connect to Snowflake database.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!