
Adding S3 specific properties to access the S3 system from Databricks
Add the S3 specific properties to the Spark configuration of your Databricks
cluster on AWS.
Before you begin
- Ensure that your Spark cluster in Databricks has been properly created and is running and its version is 3.5 LTS. For further information, see Create Databricks workspace from Databricks documentation.
- You have an AWS account.
- The S3 bucket to be used has been properly created and you have the appropriate permissions to access it.
- When you are using a Machine Learning component or tMatchPredict, you have set the Databricks Runtime Version setting to X.X LTS ML.
Procedure
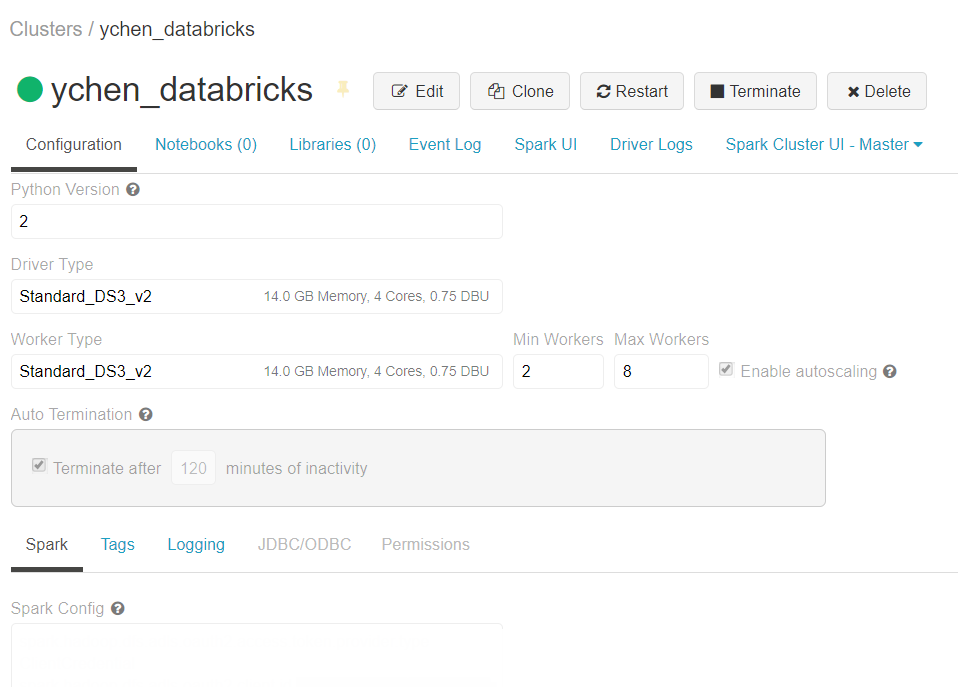
-
On the Configuration tab of your Databricks cluster
page, scroll down to the Spark tab at the bottom of the
page.
Example
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!