
Configuring the components
Procedure
-
Double-click tFixedFlowInput to open its
Basic settings view.
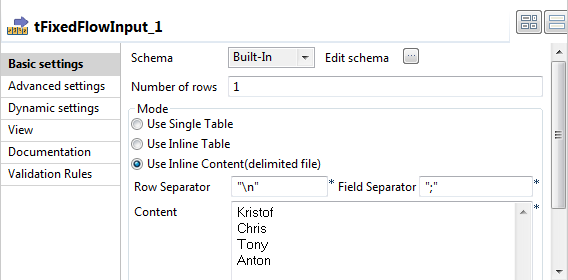
-
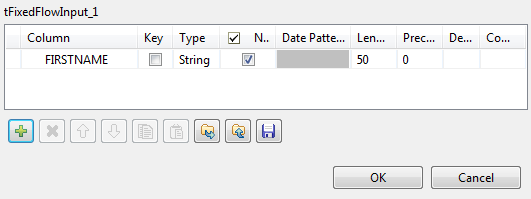
Next to the Schema field, click the
Edit schema button to open the
Schema dialog box, add one column and
name it FIRSTNAME. When done, click OK to validate these changes and close the dialog
box.
-
Double-click tSynonymSearch to open its
Basic settings view.
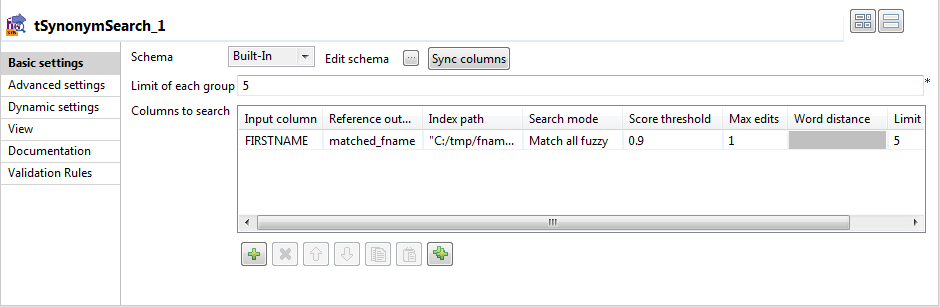
-
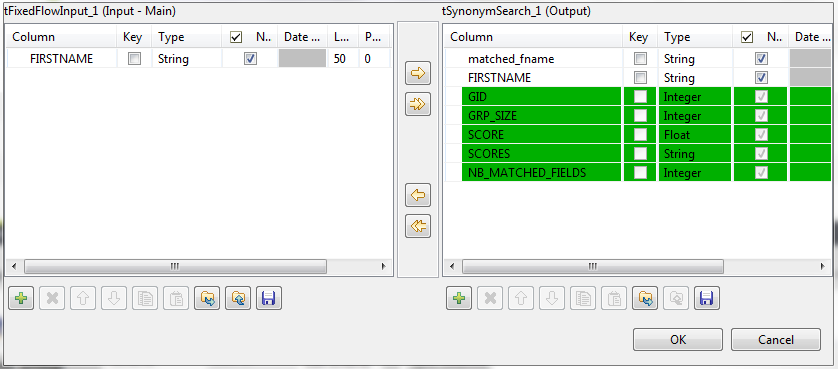
Click the [...] button next to Edit schema to open the Schema dialog box, and add one column to the output
schema: matched_fname.
This column will hold the matched reference entries in the output flow.When done, click OK to validate the setting and accept propagating the changes when prompted.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!