
Configuring the components
Procedure
-
Double-click the tFileInputDelimited component to open
its Basic settings
view.
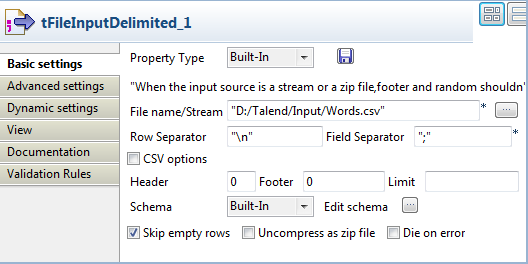
-
Click the [...]
button next to Edit
schema to open the Schema dialog box, and
set the input schema, which should contain one
column named Word
in this example.
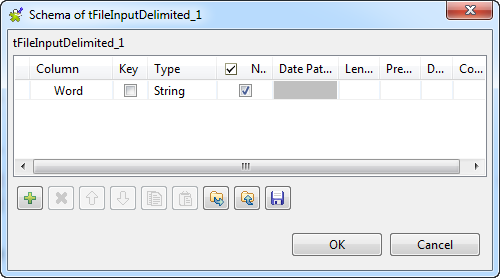 When done, click OK to close the dialog box.
When done, click OK to close the dialog box. -
Double-click the tMap
component to open the map editor. We will use this
component to map the single-column input flow to a
two-column data flow to feed the tStem component.
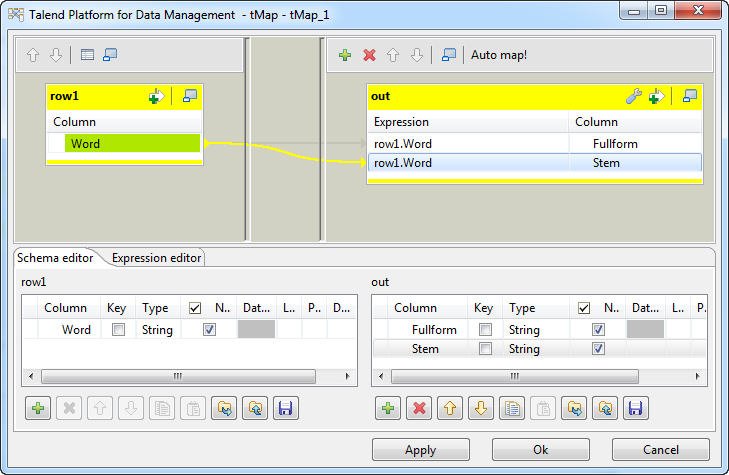
-
Double-click the tStem component to open its Basic settings view.
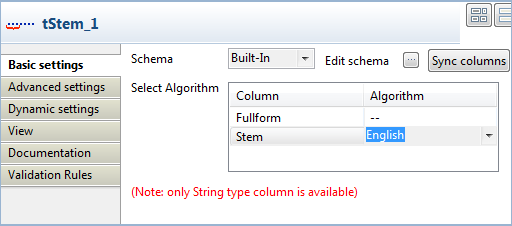
-
Double-click the tLogRow component to open its
Basic settings
view, and select the Table option for better readable
display of the Job execution result.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!