Bulk loading data from Azure DLS Gen2 into Azure Synapse
This scenario aims at helping you set up and use connectors in a pipeline. You are
advised to adapt it to your environment and use case.
Procedure
Click Connections > Add
connection.
In the panel that opens, select the type of connection you
want to create.
Example
ADLS Gen2
Select your engine
in the Engine list.
Information noteNote:
It is recommended to use the Remote Engine Gen2 rather than
the Cloud Engine for Design for advanced
processing of data.
If no Remote Engine Gen2 has been created from Talend Management Console or if it exists but appears as unavailable
which means it is not up and running, you will not be able to select
a Connection type in the list nor to
save the new connection.
The list of available connection types depends on the engine you
have selected.
Select the type of connection you want to create.
Here, select ADLS Gen2.
Fill in the connection properties to access your Azure Data Lake Storage Gen2 file
system as described in Azure Data Lake Storage Gen2 properties,
check the connection and click Add dataset.
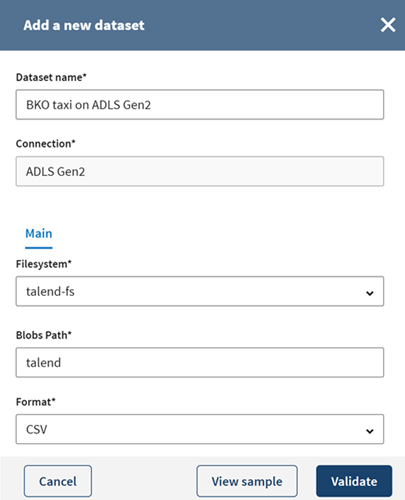
In the Add a new dataset
panel, name your dataset.
Example
BKO Taxi On ADLS Gen2
Fill in the required properties to access the file located in your storage account
and click View sample to see a preview of your dataset
sample.
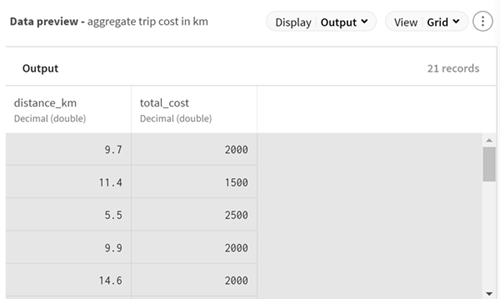
In this example, a CSV file containing data about taxi trip costs in the city of
Bamako, Mali is retrieved in the talend folder of an Azure
file system called talend-fs. You are able to see your file
system directories from the Storage Explorer page of your
Azure Storage Account.
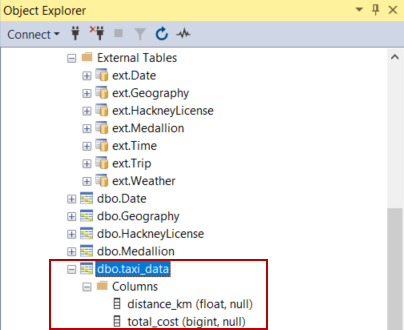
Do the same to add the Azure Synapse table that will be created when running your
pipeline, named taxi_data in this example. Fill in the
connection properties as described in Azure Synapse properties.
Click Add
pipeline on the Pipelines page. Your new pipeline opens.
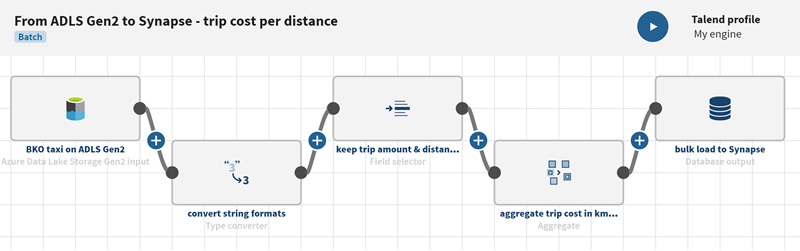
Give the pipeline a meaningful name.
Example
From ADLS Gen2 to Synapse - trip cost per distance covered
Click ADD SOURCE and select your source dataset,
BKO taxi on ADSL Gen2 in the panel that opens.
Click to add processors to the pipeline, for example a Type
converter to convert string fields to int or double type fields, a
Field selector to filter and rename some records and an
Aggregate processor to calculate the cost of a trip
according to the distance covered.
(Optional) Click the last processor to preview the processed data.
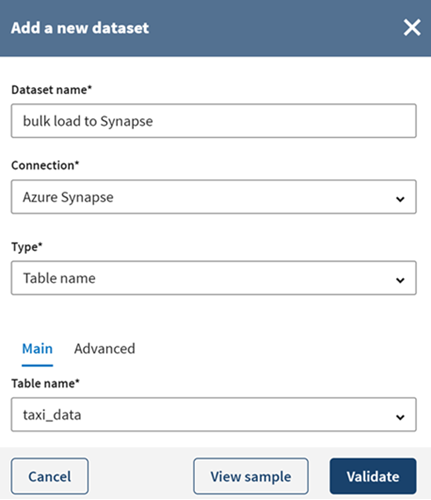
Click the ADD
DESTINATION item on the pipeline to open the panel allowing to
select the Azure Blob in which your output data will be loaded.
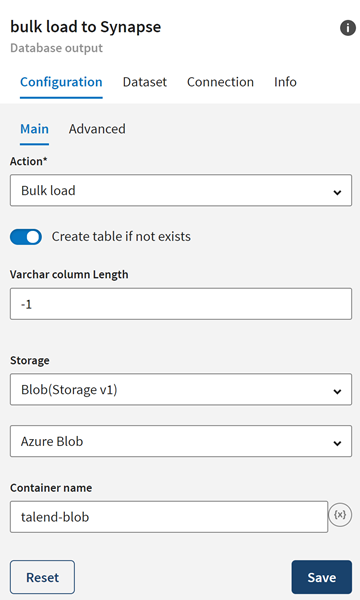
Give a meaningful name to the Destination; bulk load to
Synapse for example.
In the Configuration tab of the destination, select the
Action you want to perform on the table (Bulk
load) then select the Blob connection to be used. See Azure Blob Storage for more information on Azure Blob Storage
configuration.
Click Save to
save your configuration.
On the top toolbar of Talend Cloud Pipeline Designer,
click the Run button to open the panel allowing you to select
your run profile.
Select your run profile in the list (for more information, see Run profiles), then click Run to
run your pipeline.
Results
Your pipeline is being executed, the taxi cost information that was stored on Azure DLS
Gen2 has been aggregated per distance covered and the output flow is loaded into the
Azure Synapse table that is created when running the pipeline.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!

 In this example, a CSV file containing data about taxi trip costs in the city of Bamako, Mali is retrieved in the talend folder of an Azure file system called talend-fs. You are able to see your file system directories from the Storage Explorer page of your Azure Storage Account.
In this example, a CSV file containing data about taxi trip costs in the city of Bamako, Mali is retrieved in the talend folder of an Azure file system called talend-fs. You are able to see your file system directories from the Storage Explorer page of your Azure Storage Account.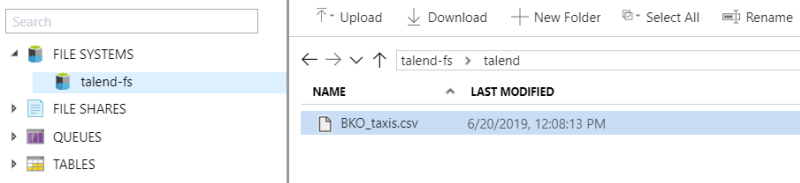
 to add processors to the pipeline, for example a Type
converter to convert string fields to int or double type fields, a
Field selector to filter and rename some records and an
Aggregate processor to calculate the cost of a trip
according to the distance covered.
to add processors to the pipeline, for example a Type
converter to convert string fields to int or double type fields, a
Field selector to filter and rename some records and an
Aggregate processor to calculate the cost of a trip
according to the distance covered.