
Sending data to a Kafka topic
This scenario aims at helping you set up and use connectors in a pipeline. You are advised to adapt it to your environment and use case.
Before you begin
- If you want to reproduce this scenario, download and extract the file: test-file-to-kafka.zip .
Procedure
-
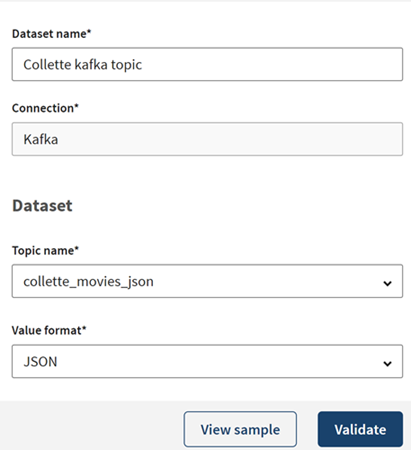
In the Add a new dataset panel, name your dataset. In this
example, the collette_movies_json topic will be used to
publish the data about movies.
Example
-
Click
 and add a Split processor to the pipeline in order to
split the records that contain both actor first names and last names. The
configuration panel opens.
and add a Split processor to the pipeline in order to
split the records that contain both actor first names and last names. The
configuration panel opens.
-
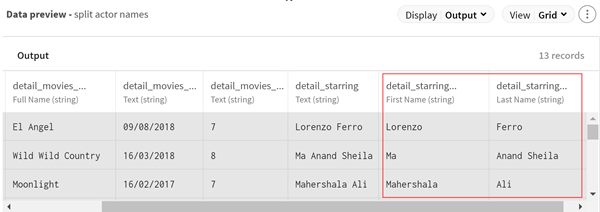
(Optional) Look at the preview of the processor to see the data after the split
operation.
-
Click and add a Filter processor to the pipeline. The
configuration panel opens.
-
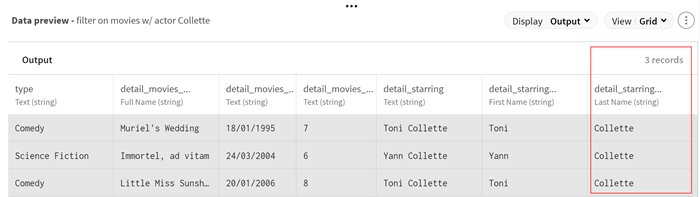
(Optional) Look at the preview of the Filter processor to
see your data sample after the filtering operation.
Example
Results
Your pipeline is being executed, the movie data from your test file has been processed and the output flow is sent to the collette_movies_json topic you have defined.
What to do next
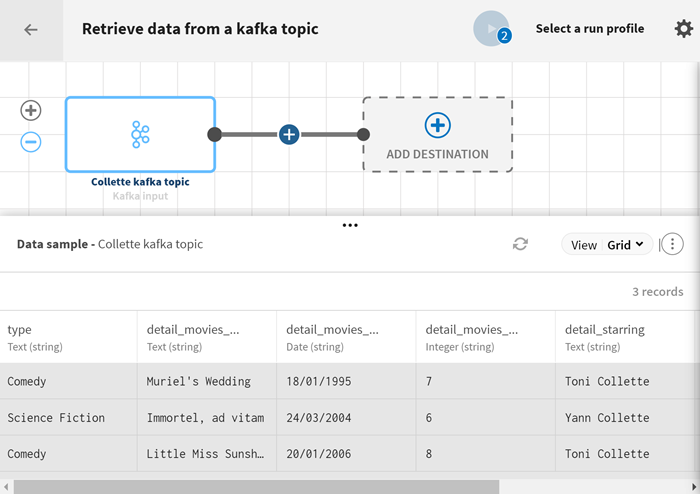
Once the data is published, you can consume the content of the topic in another pipeline and use it as a source:
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!