
Analyzing data using decision trees and the Random forest algorithm
Each partition is chosen greedily by selecting the best split from a set of possible splits, in order to maximize the information gain at a tree node. Information gain is linked with the node impurity, which measures the homogeneity of the labels at a given node.
The current implementation provides two impurity measures for classification:
- Gini impurity
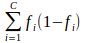
- Entropy
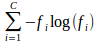 where fi is the frequency
of label i at a node.
where fi is the frequency
of label i at a node.
In order to split, each continuous feature has to be discretized. The number of bins of each feature is managed by the Max Bins parameter. Increasing the value for this parameter allows the algorithm to consider more split candidates and make fine-grained split decisions. However, it increases computation. The decision tree construction stops as soon as one of the following conditions is met:
- The node depth is equal to the maximum depth of a tree. Deeper decision trees are more expressive, but they are more resource consuming and are prone to overfitting.
- No split candidate leads to an information gain greater than Min Info Gain.
- No split candidate produces child nodes which each have at least Min Instance Per Node rows.
The Random forest algorithm runs the decision tree algorithm many times (controlled by parameter numTrees), over a subset of the dataset and a subset of the features.
The two subsets are handled by two parameters:
- Subsampling rate: This parameter specifies the fraction of the input dataset used for training each decision tree in the forest. The dataset is created by conducting sampling with replacement, meaning that a row can be present many times for example.
- Subset strategy: This parameter specifies the number of features to
be considered for each tree. You can specify one of the following values:
- auto: the strategy is automatically based on the number of trees in the forest.
- all: the total number of features is considered for split.
- sqrt: the number of features to be considered is the square root of the total number of features.
- log2: the number of features to be considered is the result of log2(M), where M is the total number of features.
This will generate different trees. New values can be predicted by taking the majority vote over the set of trees.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!