
Configuration wizard
The configuration wizard enables you to create different production environments, Configurations, and their match rules.
You can also use the configuration wizard to import match rules created and tested in Talend Studio and use them in your match Jobs. For further information, see Importing match rules from the repository.
You can not open the configuration wizard unless you link the input component to the tMatchGroup component.
Opening the configuration wizard
Procedure
-
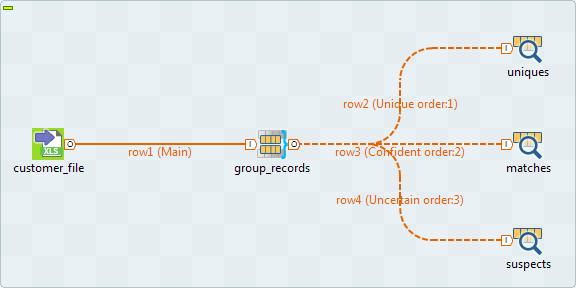
In the Talend Studio
workspace, design your Job and link the components together, for example as
below:
-
To configure tMatchGroup, do one of the
following:
- Double-click tMatchGroup or right-click it and from the contextual menu select Configuration Wizard.
- In the Basic settings view of tMatchGroup, click Preview.
Results
-
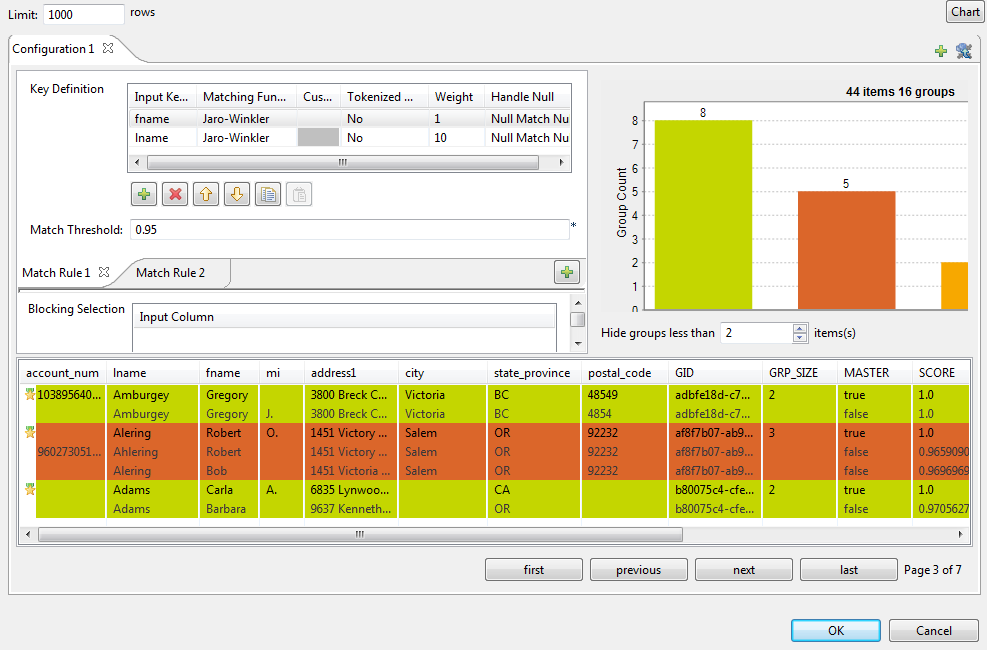
The Configuration view, where you can set the match rules and the blocking columns.
-
The matching chart, which presents the graphic matching result.
-
The matching table, which presents the details of the matching result.
The Limit field at the upper-left corner indicates the maximum number of rows to be processed by the match rule(s) in the wizard. The by-default maximum row number is 1000.
Configuration view
From this view, you can edit the configuration of the tMatchGroup component or define different configurations in which to execute the Job.
About this task
You can use these different configurations for testing purposes for example, but you can only save one configuration from the wizard, the open configuration.
In each configuration, you can define the parameters to generate match rules with the VSR or the T-Swoosh algorithm. The settings of the Configuration view differ slightly depending if you select Simple VSR or T-Swoosh in the basic settings of the tMatchGroup component.
You can define survivorship rules, blocking key(s) and multiple conditions using several match rules. You can also set different match intervals for each rule. The match results on multiple conditions will list data records that meet any of the defined rules. When a configuration has multiple conditions, the Job conducts an OR match operation. It evaluates data records against the first rule and the records that match are not evaluated against the other rules.
-
The Key definition parameters.
-
The Match Threshold field.
-
A blocking key in the Blocking Selection table (available only for rules with the VSR algorithm).
Defining a blocking key is not mandatory but advisable as it partitions data in blocks to reduce the number of records that need to be examined. For further information about the blocking key, see Importing match rules from the repository.
-
The Survivorship Rules for Columns parameters (available only for rules with the T-Swoosh algorithm).
-
The Default Survivorship Rules parameters for data types (available only for rules with the T-Swoosh algorithm).
Procedure
-
Click the [+] button on the top right corner of
the Configuration view.
This creates, in a new tab, an exact copy of the last configuration.
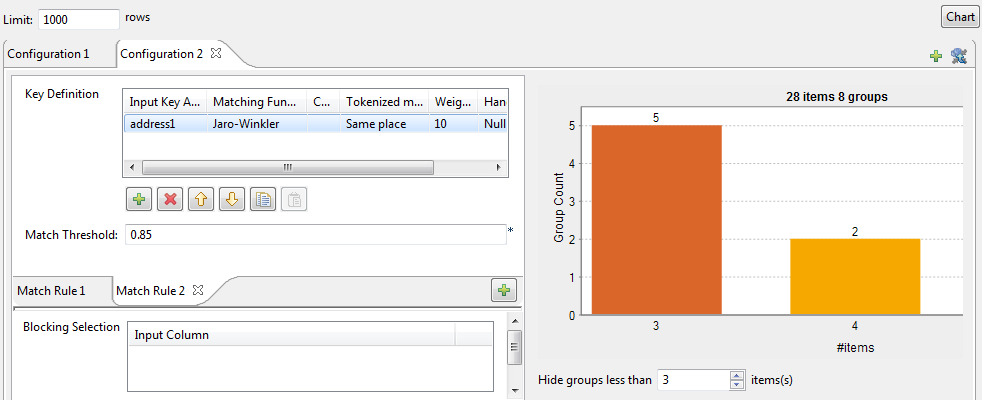
Matching chart
About this task
The Hide groups less than parameter, which is set to 2 by default, enables you to decide what groups to show in the result chart. Usually you want to hide groups of small group size.
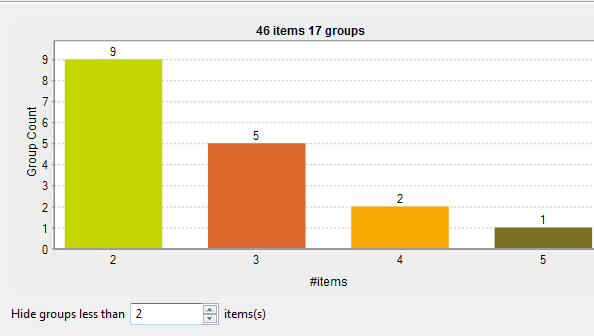
-
46 items are analyzed and classified into 17 groups according to a given match rule and after excluding items that are unique, by setting the Hide groups less than parameter to 2.
-
9 groups have 2 items each. In each group, the 2 items are duplicates of each other.
-
5 groups have 3 items each. In each group, these items are duplicates of one another.
-
2 groups have 4 items each. In each group, these items are duplicates of one another.
-
One single group has 5 duplicate items.
Matching table
About this task
This table indicates the matching details of items in each group and colors the groups in accordance with their color in the matching chart.

You can decide what groups to show in this table by setting the Hide groups of less than parameter. This parameter enables you to hide groups of small group size. It is set to 2 by default.
The buttons under the table helps you to navigate back and forth through pages.