
Generating the matching model
Procedure
-
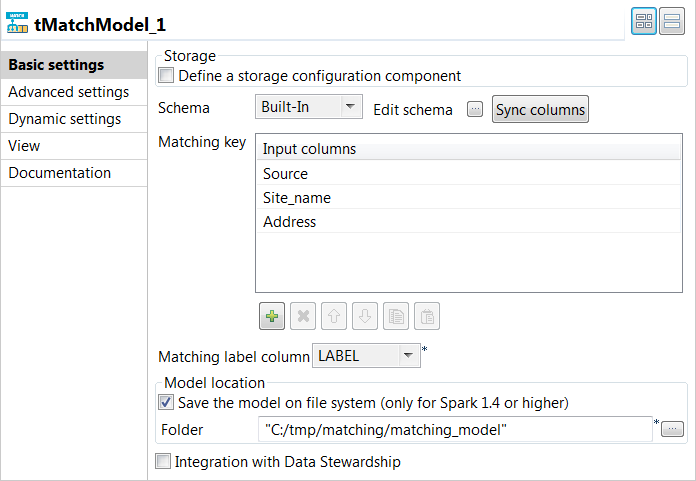
Double-click tMatchModel to display the
Basic settings view and define the component
properties.
Results
You can now use this model with the tMatchPredict component to label all the duplicates computed by tMatchPairing.
For further information, see Labeling suspect pairs with assigned labels.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!