
T-Swoosh algorithm
-
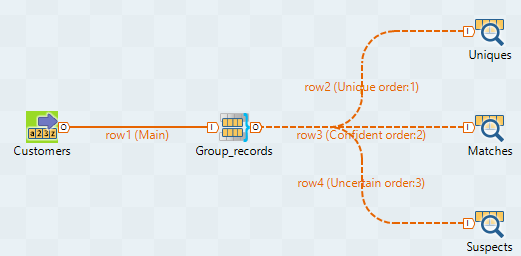
Uniques: lists the records which group size (minimal distance computed in the record) is equal to 1.
-
Matches: lists the records which group quality is greater than or equal to the threshold you define in the Confident match threshold field.
-
Suspects: lists the records which group quality is less than the threshold you define in the Confident match threshold field.
This scenario applies only to Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend MDM Platform, Talend Data Services Platform, Talend MDM Platform and Talend Data Fabric.
Setting up the Job
Procedure
-
Connect tMatchGroup to
the three tLogRow components using the
Uniques, Matches and Suspects
links.
Configuring the input component
About this task
The input data contain seven columns: lname, fname, middle_name, address, city, state_province and postal_code. The data have problems such as duplication, names spelled differently or wrongly, different information for the same customer.
Procedure
- Double-click the tFixedFlowInput component to display its Basic settings view.
- Select Built-in and click the […] button next to Edit Schema.
- Define the seven columns and click OK.
- Select Use Inline Content(delimited file).
- Fill in the Row Separator and Field Separator fields.
- Enter the input data in the Content field.
Configuring the tMatchGroup component
Procedure
-
Click the Chart button
to execute the Job in the defined configuration and have the matching results
directly in the wizard.
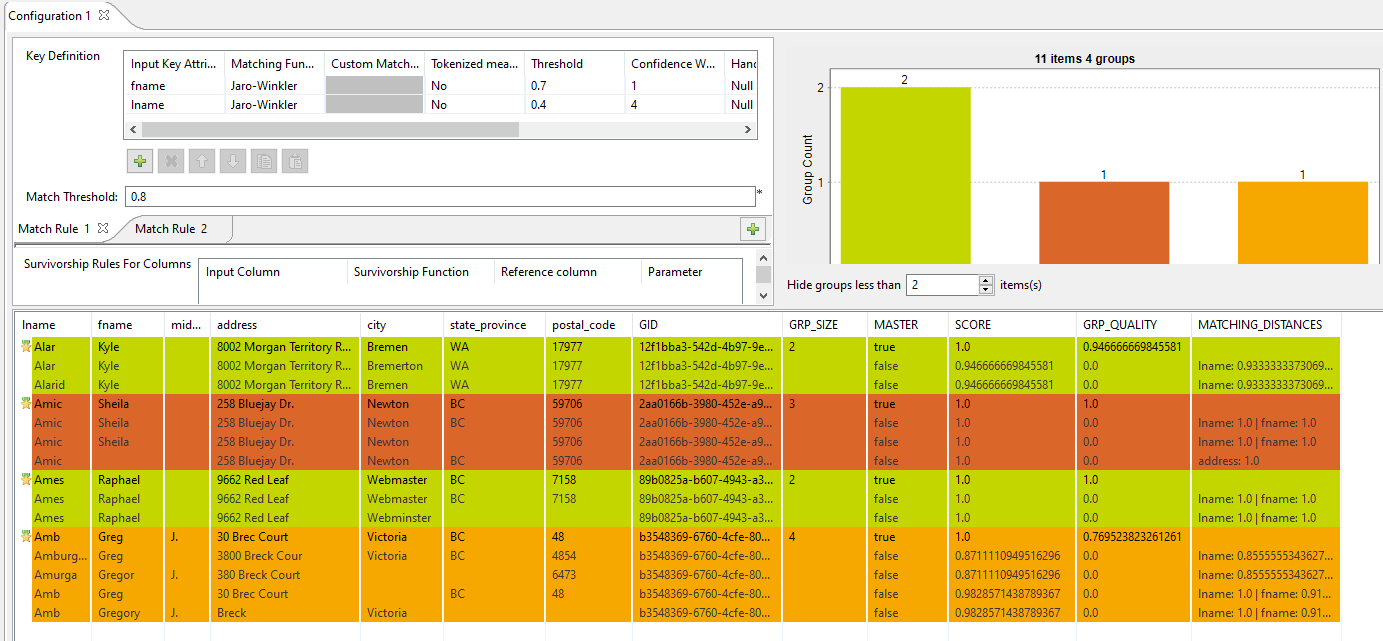 The matching chart gives a global picture about the duplicates in the analyzed data. The matching table indicates the details of items in each group and colors the groups in accordance with their color in the matching chart.The Job conducts an OR match operation on the records. It evaluates the records against the rule. The MATCHING_DISTANCES column allows you to understand which rule has been used on what records.
The matching chart gives a global picture about the duplicates in the analyzed data. The matching table indicates the details of items in each group and colors the groups in accordance with their color in the matching chart.The Job conducts an OR match operation on the records. It evaluates the records against the rule. The MATCHING_DISTANCES column allows you to understand which rule has been used on what records.For example, in the second data group (brick red), the last Amic record is matched according to the second rule that uses address1 as a key attribute, whereas the other records in the group are matched according to the first rule which uses the lname and fname as key attributes.
As you can see in this example, the value in the GRP_QUALITY column can be less than the Match Threshold parameter. That is because a group is created from record pairs with a matching score greater than or equal to the Match Threshold but the records are not all compared to each other; whereas GRP_QUALITY takes into account all record pairs in the group.
Finalizing the Job and executing it
Procedure
- Double-click each tLogRow component to display the Basic settings view.
- Select Table (print values in cells of a table).
- Save your Job and press F6 to execute it.
Results
You can see that records are grouped together in three different groups. Each record is listed in one of the three groups according to the value of the group score which is the minimal distance computed in the group.
The identifier for each group, which is of String data type, is listed in the GID column next to the corresponding record. This identifier is of the data type Long for Jobs that are migrated from older releases. To have the group identifier as String, replace the tMatchGroup component in the imported Job with tMatchGroup from the Talend Studio Palette.
The number of records in each of the three output blocks is listed in the GRP_SIZE column and computed only on the master record. The MASTER column indicates with true or false whether the corresponding record is a master record or not. The SCORE column lists the calculated distance between the input record and the master record according to the Jaro-Winkler and Jaro matching algorithms.
The Job evaluates the records against the first rule and the records that match are not evaluated against the second rule.
All records with a group score between the match interval, 0.95 or 0.85 depending on the applied rule, and the confidence threshold defined in the advanced settings of tMatchGroup are listed in the Suspects output flow.

All records with a group score greater than or equal to one of the match probabilities are listed in the Matches output flow.
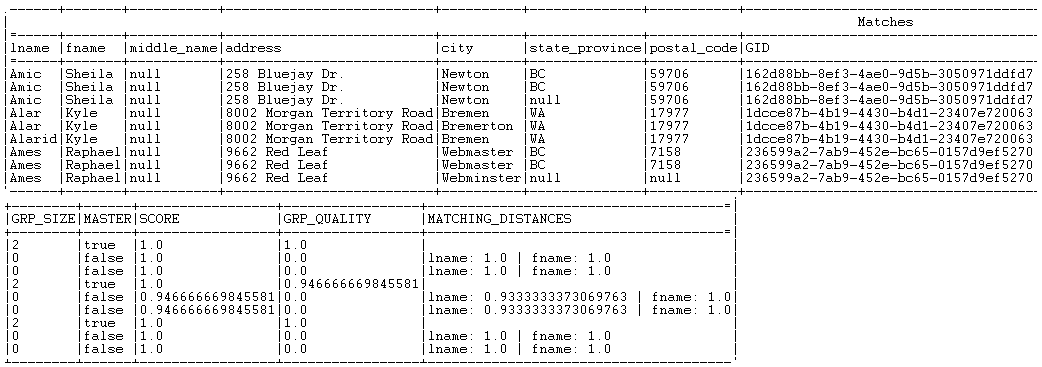
All records with a group size equal to 1 is listed in the Uniques output flow.

For another scenario that groups the output records in one single output flow, see Comparing columns and grouping in the output flow duplicate records that have the same functional key in the Identification section.