
Automatically standardizing values in a column
You can use the Standardize value (fuzzy matching) to find the closest valid value for invalid values within a column.
The function checks the invalid data contained in a column against the current semantic type, and retrieves the correct values, if the selected matching threshold is achieved. This function is only available if the semantic type is based on a dictionary of values present by default in Talend Data Preparation, or that you have created using Talend Dictionary Service. For more information on how to create custom semantic types, or edit the existing ones, see Enriching the semantic types libraries.
Let's say that you have to work on a dataset containing various information on customers based in the United-States, such as their names, email addresses and the State they live in.
As you can see in the header of the State column, the data has been recognized as US States, but as shown in the quality bar, some of the entries contain invalid names.
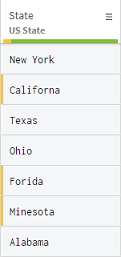
In a single action, you will fix those invalid values, and replace them with the correct value from the US State dictionary, or semantic type, that contains an exhaustive list of all the US States.
Procedure
-
Point your mouse over the Submit button to preview
result of the function, and click to apply it.

Results
The incorrect values have been standardized, using the dictionary of US States.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – let us know how we can improve!